
L'intelligence artificielle (IA) est une branche de l'informatique qui transforme littéralement, et ce depuis plusieurs années, la recherche scientifique et l'industrie. Récemment, des scientifiques se sont bien rendus compte qu'elle pourrait également accélérer le développement d'une fusion nucléaire sûre, propre, efficace et pratiquement illimitée pour produire de l'électricité.
Un pas important dans cette direction est en cours au Princeton Plasma Physics Laboratory (PPPL) du Département de l'énergie des États-Unis (DOE) et à l'Université de Princeton, où une équipe de scientifiques collaborant avec un étudiant diplômé de Harvard applique pour la première fois l'apprentissage profond (deep learning) une nouvelle forme très puissante d'apprentissage automatique pour prévoir les perturbations soudaines qui peuvent arrêter les réactions de fusion et endommager les tokamaks (les chambres en forme de donuts) qui contiennent les réactions.
« Cette recherche ouvre un nouveau chapitre prometteur dans l'effort visant à apporter une énergie illimitée à la Terre », a déclaré Steve Cowley, directeur du PPPL, au sujet des résultats, publiés dans le dernier numéro de la revue Nature. « L'intelligence artificielle explose à travers les sciences et maintenant, elle commence à contribuer à la quête mondiale de la fusion nucléaire ».
La fusion nucléaire, qui anime le Soleil et les étoiles, consiste en la fusion d'éléments sous forme de plasma l'état chaud et chargé de la matière, composé d' électrons libres et de noyaux atomiques qui génère de l'énergie. Les scientifiques cherchent à reproduire la fusion sur Terre pour obtenir un approvisionnement abondant en énergie pour la production d'électricité.
Pour démontrer la capacité de l'apprentissage automatique profond à prévoir les perturbations au sein d'un tokamak la perte soudaine de confinement des particules plasmatiques et de l'énergie l'accès à d'énormes bases de données fournies par deux grandes installations de fusion : la DIII-D National Fusion Facility que General Atomics exploite pour le DOE en Californie (la plus grande installation aux États-Unis), et le Joint European Torus (JET) au Royaume-Uni, la plus grande installation (tokamak) au monde, gérée par EUROfusion, le Consortium européen pour le développement de l'énergie de fusion. Le soutien des scientifiques du JET et du DIII-D a été essentiel pour ces travaux.
Les vastes bases de données ont permis de prévoir de façon fiable les perturbations dans les tokamaks autres que ceux sur lesquels le système a été formé dans ce cas-ci, du "petit" tokamak DIII-D au grand JET. Cette réalisation est de bon augure pour la prévision de perturbations sur ITER, un tokamak beaucoup plus grand et plus puissant qui devra appliquer les capacités acquises dans les installations de fusion actuelles.
Le code d'apprentissage profond, appelé Fusion Recurrent Neural Network (FRNN), ouvre également des voies possibles pour contrôler et prédire les perturbations.
Le domaine le plus intrigant de la croissance scientifique
« L'intelligence artificielle est le domaine le plus intrigant de la croissance scientifique à l'heure actuelle, et l'associer à la science de la fusion est très excitant », a déclaré Bill Tang, physicien principal de recherche au PPPL, co-auteur du document et maître de conférences au Département des sciences astrophysiques de l'Université de Princeton. Il supervise le projet AI. « Nous avons accéléré la capacité de prédire avec une grande précision le défi le plus dangereux pour une énergie de fusion propre ».
Contrairement aux logiciels traditionnels, qui exécutent des instructions prescrites, l'apprentissage profond apprend de ses erreurs. Les réseaux neuronaux, les couches de nœuds interconnectés (principalement des algorithmes mathématiques) qui sont "paramétrés" ou pondérés par le programme pour façonner la sortie désirée, complètent cette magie apparente.
Pour une entrée donnée, les nœuds cherchent à produire une sortie spécifiée, telle que l'identification correcte d'un visage ou des prévisions précises d'une perturbation. L'entraînement commence lorsqu'un nœud ne parvient pas à accomplir cette tâche : les poids s'ajustent automatiquement pour les nouvelles données, jusqu'à ce que la sortie correcte soit obtenue.
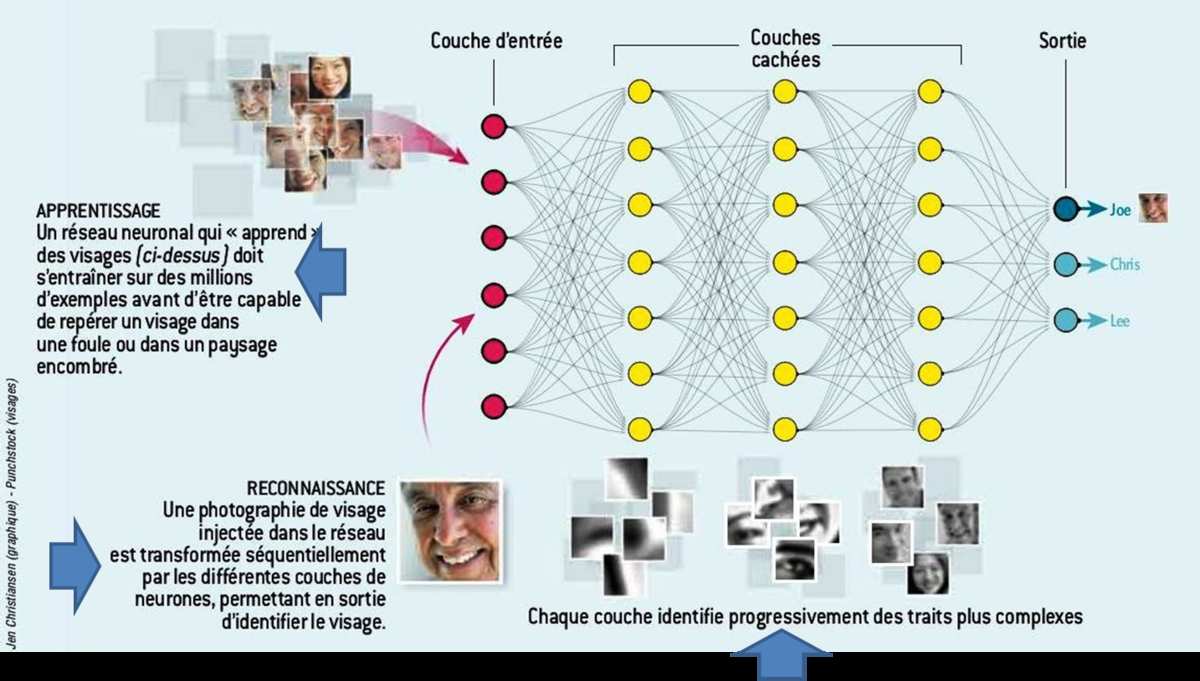
Schéma expliquant le principe d'apprentissage profond dans le cadre de la reconnaissance faciale. Crédits : Jen Christansen/ Pushstock
Sur le même sujet : Le réacteur à fusion nucléaire chinois EAST atteint une température record de 100 millions de °C
Une caractéristique clé de l'apprentissage profond est sa capacité à saisir des données à plusieurs dimensions plutôt que des données unidimensionnelles. Par exemple, alors qu'un logiciel d'apprentissage non approfondi peut prendre en compte la température d'un plasma à un moment donné, le FRNN prend en compte les profils de la température qui se développe dans le temps et l'espace.
« La capacité des méthodes d'apprentissage profond à apprendre à partir de données aussi complexes en fait un candidat idéal pour la tâche de prédiction des perturbations », a déclaré le collaborateur Julian Kates-Harbeck, étudiant diplômé en physique à l'Université Harvard, auteur principal du document paru sur Nature et concepteur en chef de l'algorithme.
La formation et l'exploitation des réseaux neuronaux reposent sur des unités de traitement graphique (GPU), des puces informatiques conçues en premier lieu pour calculer des images 3D. Ces puces sont idéales pour les applications d'apprentissage profond et sont largement utilisées par les entreprises pour implémenter des capacités d'IA telles que la compréhension de la langue parlée ou l'observation des conditions routières par les voitures autonomes.
Kates-Harbeck a basé la conception du code FRNN sur plus de deux téraoctets de données recueillies par le JET et le DIII-D. Après avoir exécuté le logiciel sur le cluster de GPU modernes Tiger de l'Université de Princeton, l'équipe l'a placé sur Titan, un supercalculateur de l'Oak Ridge Leadership Computing Facility ainsi que sur d'autres machines hautes performances.
Une tâche exigeante
Répartir le réseau sur de nombreux ordinateurs était une tâche exigeante. « La formation des réseaux neuronaux profonds est un problème de calcul intensif qui nécessite l'engagement de clusters de calcul haute performance », a déclaré Alexey Svyatkovskiy, co-auteur de l'étude et qui a aidé à convertir les algorithmes en un code de production. « Nous avons placé une copie de l'ensemble de notre réseau neuronal à travers de nombreux processeurs pour obtenir un traitement en parallèle très efficace », ajoute-t-il.
Le logiciel a en outre démontré sa capacité à prédire les vraies perturbations dans le délai de 30 millisecondes dont ITER aura besoin, tout en réduisant le nombre de fausses alarmes. Le code se rapproche maintenant de l'exigence ITER, avec 95% de prévisions correctes et moins de 3% de faux positifs.
Bien que les chercheurs affirment que seule une opération expérimentale en direct peut démontrer les mérites de toute méthode prédictive, leur article note que les grandes bases de données archivistiques utilisées dans les prédictions couvrent un large éventail de scénarios opérationnels et fournissent ainsi des preuves significatives quant aux forces relatives des méthodes considérées dans cet article.
La prochaine étape consistera à passer de la prévision au contrôle des perturbations. « Plutôt que de prédire les perturbations au dernier moment et de les atténuer ensuite, nous utiliserions idéalement les futurs modèles d'apprentissage profond pour éloigner doucement le plasma des régions d'instabilité, dans le but d'éviter la plupart des perturbations en premier lieu », explique Kates-Harbeck.
Michael Zarnstorff, qui est récemment passé du poste de directeur adjoint de la recherche au PPPL à celui de directeur scientifique en chef du laboratoire, souligne cette nouvelle étape. « Le contrôle sera essentiel pour les tokamaks post-ITER, pour lesquels l'évitement des perturbations sera une exigence essentielle », a noté M. Zarnstorff.
Pour passer des prédictions précises basées sur l'intelligence artificielle à un contrôle réaliste du plasma, il faudra par contre plus d'une discipline. « Nous combinerons l'apprentissage profond avec la physique de base sur des ordinateurs à haute performance pour nous concentrer sur des mécanismes de contrôle réalistes dans la combustion des plasmas » a déclaré M. Tang. « Par contrôle, nous entendons savoir quels "boutons tourner" sur un tokamak pour changer les conditions permettant d'éviter les perturbations. C'est dans notre ligne de mire, et c'est là que nous allons ».