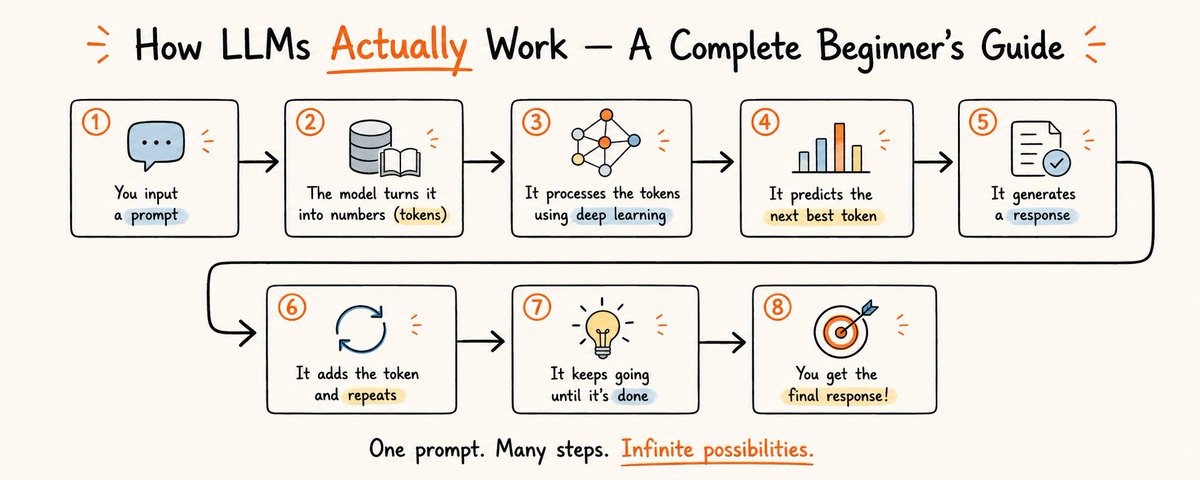
You've used them. You've been amazed by them. You may have also been confused, annoyed, or even a little spooked by them. But do you actually know what a Large Language Model is doing when you type a question and it fires back a fluent, confident, paragraph-long answer?
Most people imagine a tiny genius living inside the computer. The truth is stranger — and far more interesting. By the end of this guide, you'll understand LLMs better than 95% of the people casually throwing the term around. Let's pull back the curtain.
1. What an LLM Actually Is
LLM stands for Large Language Model. Let's break that down literally:
Word
What it means
In plain EnglishLarge
Hundreds of billions of internal settings ("parameters")
It's enormous — trained on a huge slice of the internetLanguage
It works with text — words, code, symbols
Its whole world is languageModel
A mathematical pattern-finder
A super-powered statistical guessing machine
Here's the part that surprises everyone: at its core, an LLM is essentially a fancy autocomplete. It does not "think," "know," or "understand" the way a human does. It's a system that has read an astonishing amount of text and learned, with eerie precision, what word tends to come next.
◆ MENTAL MODEL Think of an LLM as the autocomplete on your phone — but one that swallowed most of the internet, books, code, and Wikipedia, and then practiced predicting the next word a trillion times.
2. The One Trick: Predicting the Next Word
Everything an LLM does grows out of one humble skill: guessing what comes next.
Imagine I give you this sentence and ask you to finish it:
"The sky is ___"
Your brain instantly offers candidates: blue, cloudy, falling, clear. You also rank them — "blue" feels far more likely than "spaghetti." That ranking is exactly what an LLM does, except it does it for every possible word in its vocabulary, assigning each a probability.
What the model "sees" after: "The sky is..." (Illustrative probabilities the model might assign to the next word)
plaintext
blue ████████████████████████████ 62%
clear ████████ 18%
cloudy █████ 12%
falling ██ 5%
spaghetti ▌ 1% The model picks a word (usually a likely one, with a dash of randomness for variety), adds it to the sentence, and then repeats the whole process — predicting the next word, and the next, and the next. String thousands of these predictions together and you get essays, code, poems, and emails.
[🧶] ANALOGY It's like knitting a scarf one stitch at a time. Each stitch (word) depends on the ones before it. The model never sees the "whole scarf" in advance — it just keeps adding the most sensible next stitch until you tell it to stop.
3. Tokens: How AI Actually Reads
Before predicting anything, the model chops text into "tokens."
Here's a subtle but crucial detail: LLMs don't read words the way we do. They break text into tokens — chunks that might be a whole word, part of a word, or even a single character. The model thinks entirely in these tokens and the numbers attached to them.
✓ WHY THIS MATTERS TO YOU "Context windows" and pricing are measured in tokens, not words. When a tool says it handles "128K tokens," that's roughly a 300-page book it can keep in mind at once. It also explains why LLMs sometimes miscount letters in a word — they don't see letters, they see tokens.
| What it means | In plain English | |
| Large | Hundreds of billions of internal settings ("parameters") | It's enormous — trained on a huge slice of the internet |
| Language | It works with text — words, code, symbols | Its whole world is language |
| Model | A mathematical pattern-finder | A super-powered statistical guessing machine |
Text
Approx. tokens
Notescat
1 token
Common short word = 1 chunkunbelievable
3-4 tokens
Split into pieces like un · believ · able1 page of text (~500 words)
~650 tokens
Rule of thumb: 1 word ≈ 1.3 tokens
4. How an LLM Is Trained (in 3 Stages)
Training turns a blank statistical machine into a helpful assistant.

A raw model fresh off the assembly line is useless — it's like a brain with no memories. Turning it into ChatGPT or Claude happens in three big stages.
1. Pre-training — "Read the internet" The model is fed an enormous amount of text (books, websites, code) and does one thing billions of times: predict the next token. This is where it absorbs grammar, facts, reasoning patterns, and writing styles. Expensive and slow — this is the "large" in LLM.
2. Supervised fine-tuning — "Learn to be an assistant" Humans write example conversations showing ideal answers. The model learns the format of being helpful: answering questions, following instructions, being polite.
3. Reinforcement learning from human feedback (RLHF) — "Learn what people prefer" Humans rate answers as better or worse. The model is nudged toward responses people like and away from harmful or unhelpful ones. This is the "polish" that makes it feel friendly and safe.
| Approx. tokens | Notes | |
| cat | 1 token | Common short word = 1 chunk |
| unbelievable | 3-4 tokens | Split into pieces like un · believ · able |
| 1 page of text (~500 words) | ~650 tokens | Rule of thumb: 1 word ≈ 1.3 tokens |
Stage
Goal
Who's involved
ResultPre-training
Learn language & facts
Mostly machines + data
Knows a lot, but ramblesFine-tuning
Learn to answer
Human-written examples
Acts like an assistantRLHF
Learn preferences
Human raters
Helpful, safe, polite
◆ KEY INSIGHT The model's "knowledge" is frozen at the moment training ended. That's why an LLM may not know about events after its training cutoff — unless it's connected to live search or tools.
5. So What's Actually "Inside" the Model?
There's no database of facts, no folder of answers, no little library. Instead, everything the model learned is compressed into parameters — billions of numerical "dials" (also called weights). During training, these dials are tuned ever so slightly, over and over, until the model gets good at prediction.
You can think of a trained LLM as a lossy, compressed summary of everything it read — like a blurry JPEG of the internet.
This is also why LLMs are sometimes described as black boxes: even the engineers who build them can't point to a specific dial and say "that's where it stores the capital of France." The knowledge is smeared across billions of numbers working together.
[🎚️] ANALOGY Imagine a giant sound mixing board with 175 billion knobs. Training is the process of nudging every knob a hair at a time until the music (the predictions) sounds right. Nobody can tell you what any single knob "does" — but together they make beautiful music.
6. Why LLMs Confidently Make Things Up
"Hallucination" is a feature of how prediction works — not a random bug.

Because an LLM's only true skill is generating plausible-sounding text, it will sometimes produce something that sounds perfectly confident but is completely wrong. This is called a hallucination.
The model isn't lying — it has no concept of truth. It's simply predicting words that "fit," and a wrong fact can fit just as smoothly as a right one. A fake book title or a made-up statistic is statistically shaped like a real one.
[⚠] IMPORTANT Never trust an LLM blindly for facts, figures, citations, legal, or medical information. Treat it as a brilliant, fast, occasionally-overconfident intern — always verify anything that matters.
| Goal | Who's involved | Result | Pre-training | Learn language & facts | Mostly machines + data | Knows a lot, but rambles | |
| Fine-tuning | Learn to answer | Human-written examples | Acts like an assistant | ||||
| RLHF | Learn preferences | Human raters | Helpful, safe, polite |
{kind=link}
Plays to its strengths
{kind=link}
Verify carefullyDrafting, rewriting, summarizing
Specific facts, dates, statisticsBrainstorming & outlining
Citations and quotes (often invented)Explaining concepts simply
Math & precise calculationsTranslating & changing tone
Recent news after its cutoffWriting & debugging code
Legal, medical, financial advice
7. How to Actually Use Them Well
Understanding the machinery makes you dramatically better at using it. A few principles that follow directly from how LLMs work:
1. Give rich context — Since the model only "knows" what's in the conversation plus its training, the more relevant detail you provide, the better its predictions.
2. Be specific about the output — Ask for the format, tone, length, and audience. "Explain like I'm 12, in 3 bullet points" beats "explain this."
3. Iterate, don't expect perfection — Treat it as a back-and-forth. Refine its answer the way you'd coach a junior teammate.
4. Verify the important stuff — Use it to draft and think — but fact-check anything with real-world consequences.
✓ PRO TIP: PROMPTING IS A SKILL The quality of your output is shaped massively by the quality of your input. Learning to "prompt" well is the single highest-leverage skill for getting value from AI — and it requires zero coding. (See the free guides below.)
8. Key Takeaways
| abs.twimg.com Verify carefully | Drafting, rewriting, summarizing | Specific facts, dates, statistics | |
| Brainstorming & outlining | Citations and quotes (often invented) | ||
| Explaining concepts simply | Math & precise calculations | ||
| Translating & changing tone | Recent news after its cutoff | ||
| Writing & debugging code | Legal, medical, financial advice |
#
Remember this1
An LLM is a giant next-word predictor — a supercharged autocomplete.2
It reads in
tokens
, not words or letters.3
It's trained in 3 stages: pre-training → fine-tuning → human feedback.4
Its "knowledge" lives in billions of numerical dials, not a database.5
It can hallucinate — confidently wrong — so always verify facts.6
Better context + clearer prompts = dramatically better results.
[📚] Want to Go Deeper ? Recommended Reading
If this guide sparked your curiosity, these accessible books take you further without overwhelming you:
- Co-Intelligence: Living and Working with AI — by Ethan Mollick. The best non-technical book on actually using AI in daily life and work. Practical, friendly, and grounded.
- The Coming Wave — by Mustafa Suleyman. A big-picture look at where AI is heading and what it means for society — by a co-founder of DeepMind.
- You Look Like a Thing and I Love You — by Janelle Shane. A hilarious, genuinely beginner-friendly intro to how AI thinks (and gloriously fails). Perfect first read.
[🎁] Keep Learning — Free Beginner Guides
Now that you understand how LLMs work, the next step is putting them to work — for your job, your studies, or your income. These free, beginner-friendly resources are a great place to start: