Nous avons largement démonté hier l'étude préliminaire, puis aujourd'hui l'étude finale comportant d'énormes failles méthodologiques du EU DisinfoLab sur l'affaire Benalla.
Beaucoup de personnes ont parlé de cette étude depuis plusieurs jours, discutant son bien-fondé ou non, mais bien peu se sont arrêtés sur un fait extrêmement problématique pour les libertés publiques.
En effet, l'EU DisinfoLab a, par le biais de Nicolas Vanderbiest, réalisé une étude sur les tweets liés à l'affaire Benalla. Nous laisserons aujourd'hui les conclusions de côté pour nous intéresser à la question des outils utilisés.
- Visibrain, ou Big Brother à la maison
- Que prévoient les conditions d'utilisation Twitter ?
- Quand EU DisinfoLab joue avec Big Brother
- "Et c'est le drame..." : la diffusion des données personnelles
- Le fichage politique (mais pas que) par EU DisinfoLab
- Communication de EU DisinfoLab
- Position de EU DisinfoLab quant aux données sensibles
- Le CNRS aurait aussi fiché les opinions politiques de près de 200 000 personnes !
- Réglementation et Discussion
- Plainte
I. Visibrain, ou Big Brother à la maison
Comme on l'a vu, dès le 23 juillet, Nicolas Vanderbiest a sorti une première analyse sur son blog - plutôt orientée communication : Affaire Benalla sur les réseaux sociaux : où la résurrection des partis de l'opposition ( archive). On y voit quelques chiffres, qui rejoignent ses tweets :
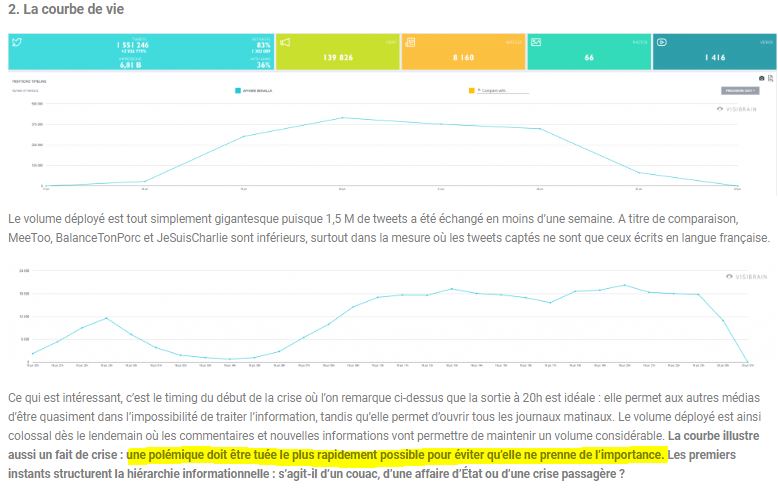

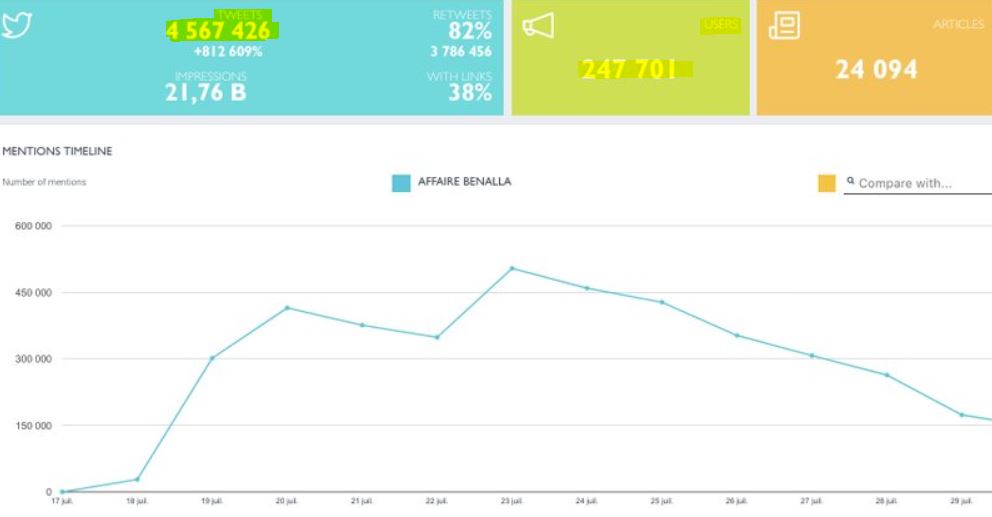
Plus précisément on voit ici qu'il s'intéresse à 4 567 426 tweets, venant de 247 701 utilisateurs :
Il utilise pour ce faire un des outils d'analyse de Twitter - il s'agit ici du logiciel Visibrain, qui sert normalement à des analyses marketing pour les grandes entreprises :

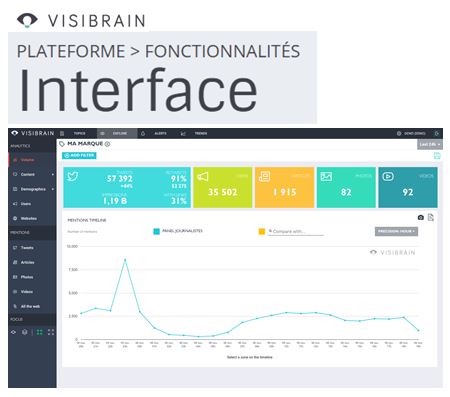
et permet de réaliser en fait automatiquement les graphiques que présente Nicolas Vanderniest :

En fait, ce logiciel (dont nous allons détailler les caractéristiques, car c'est très important) donne accès... à tous les tweets de Twitter, en temps réel (sources : 1, 2, 3) :



On peut largement filtrer, en particulier par "métiers et centres d'intérêts" ( source) :

On compte explicitement dans les Métiers "journaliste" ou... "militants politiques" ( source) :

Ah, quel est le métier le plus visé... ?
De même pour les centres d'intérêts ( source) :

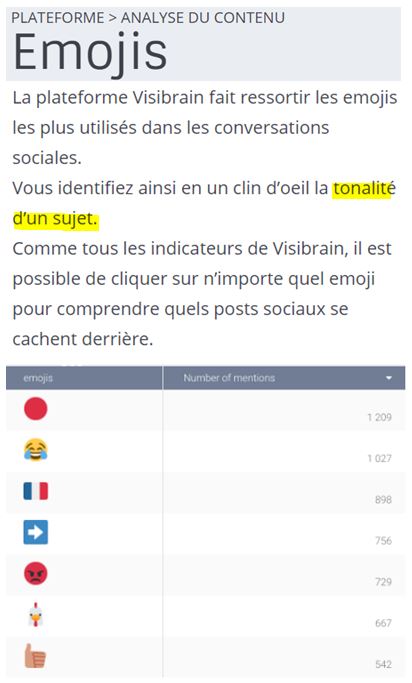
Comme on n'arrête pas le progrès, on peut même analyser les émojis ( source) :
On peut aussi chercher dans les biographies - en particulier pour trouver les "journalistes, militants et activistes" ( source) :

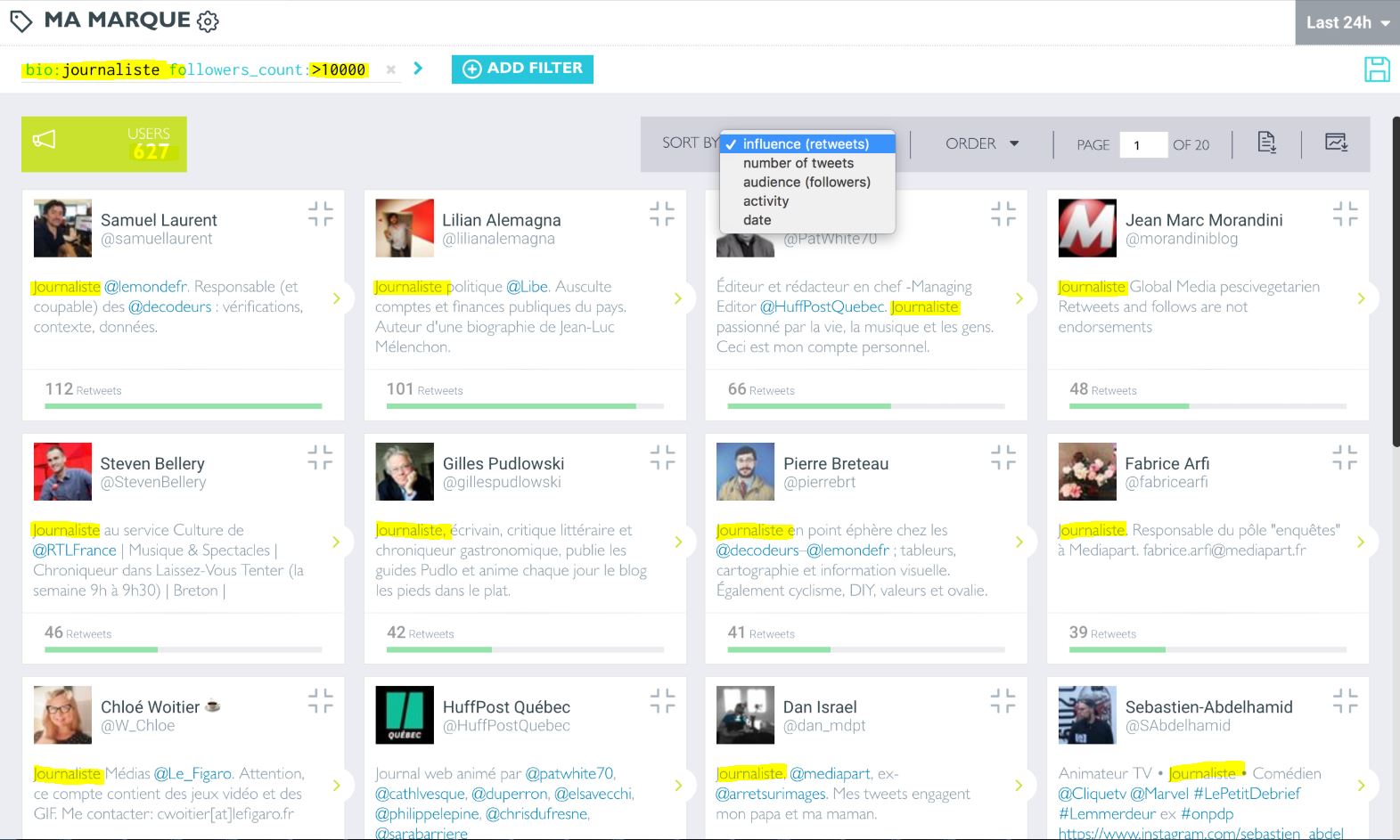
Oh des journalistes avec plus de 10 000 abonnés...
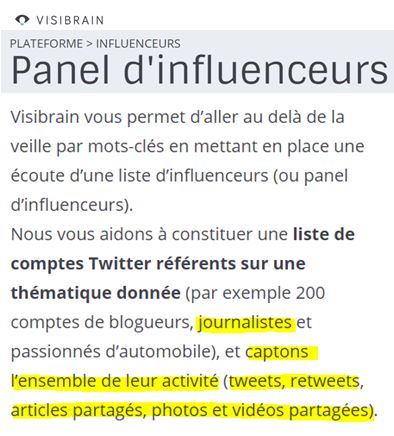
On pourra alors en faire des panels pour les suivre de très près ( source) :
De même, le logiciel déterminera généralement votre localisation et votre genre (sources : 1 et 2) :


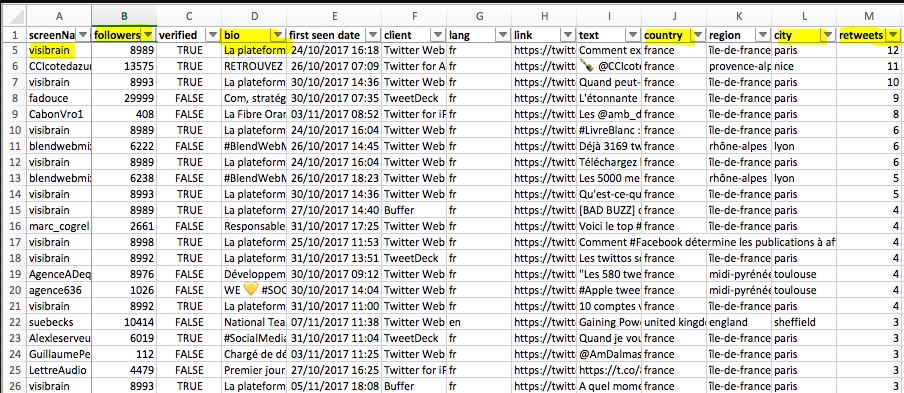
Ce logiciel Big Brother vous facilite la vie en vous permettant d'exporter toutes les données qui vous intéressent sous Excel ( source) :

Vous pouvez aussi exporter tous les followers, en les croisant ( source) :

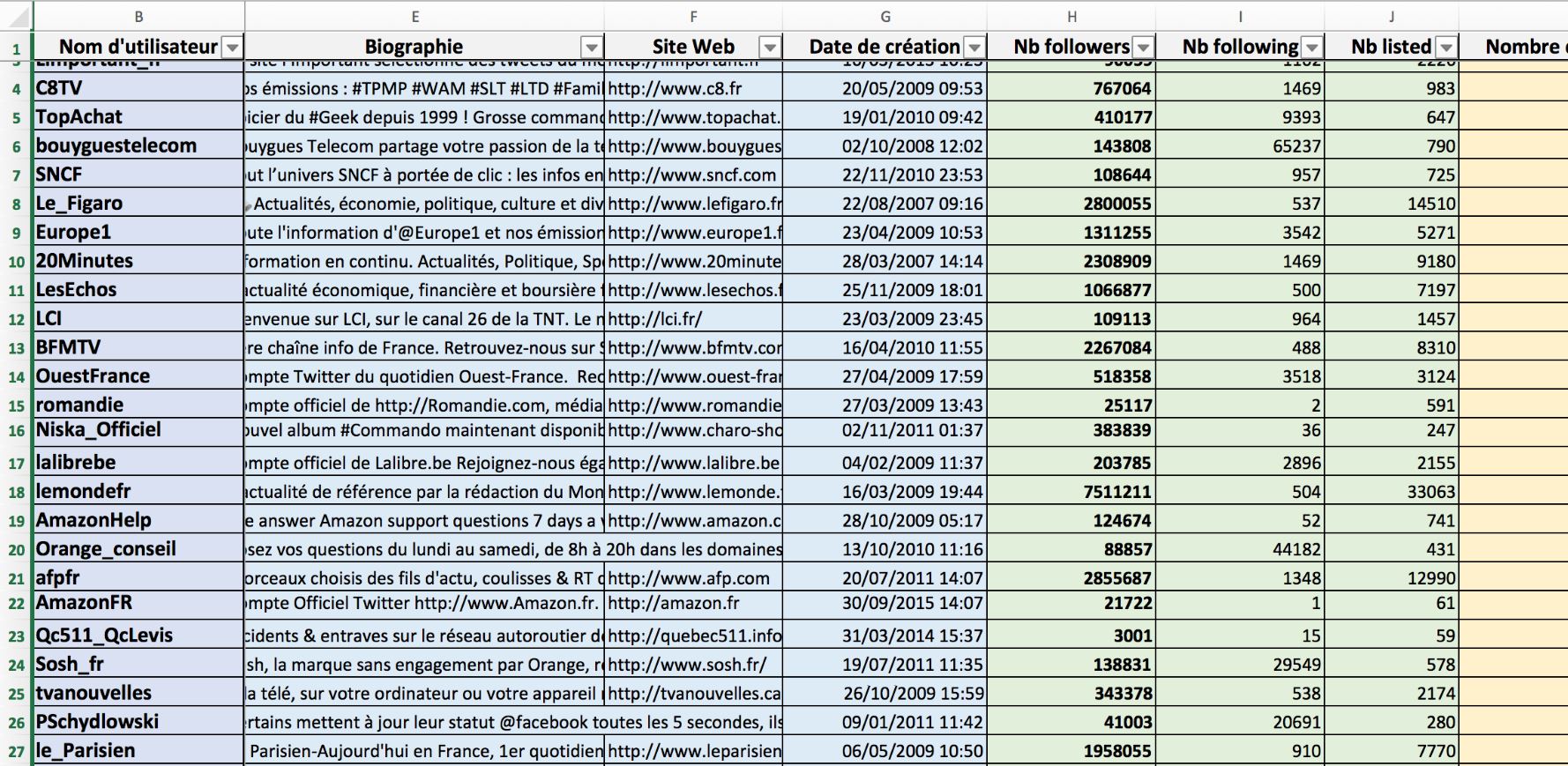
Et, si vous le souhaitez (et payez), vous pouvez même avoir accès à l'historique Twitter depuis 2006 ( source) !
Car bien sûr le logiciel est payant - comptez quelques milliers d'euros par mois pour récolter quelques centaines de milliers de tweets...
Comme vous le savez peut-être, le 25 mai 2018, le règlement européen général sur la protection des données (RGPD) est entré en application pour augmenter la protection des données des citoyens.
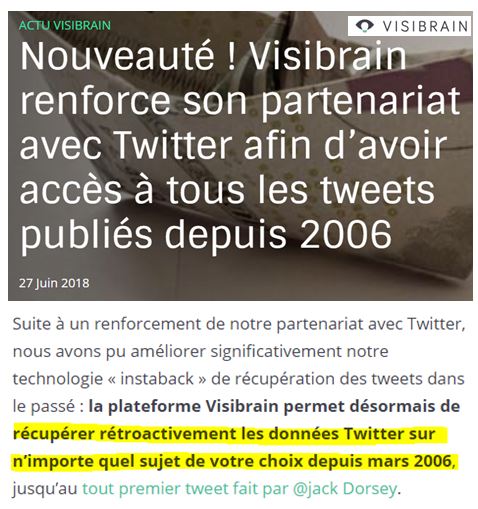
Eh bien c'est à peine le 27 juin dernier que Twitter a décidé de donner accès à ses archives à Visibrain ( source) :
II. Que prévoient les conditions d'utilisation Twitter ?
À ce stade, vous devez commencer à être effrayé de la masse d'informations mise à disposition - et de ce qu'on peut en faire...
Si vous vous demandez ce que prévoit Twitter à ce sujet, voici une sélection des conditions ( source {3}) :
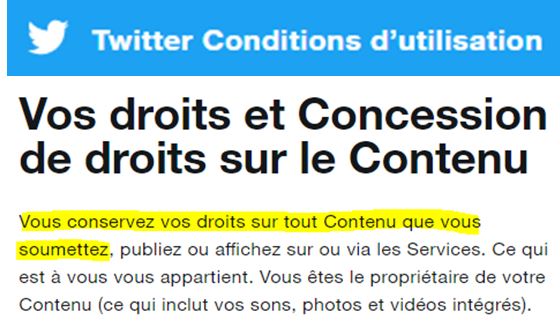
Bonne nouvelle vous conservez vos droits sur tout votre contenu !
Mais bon... :

Twitter et ses clients en font ce qu'ils en veulent et vous ne pouvez vous y opposer !
Car tout est public ( source) :
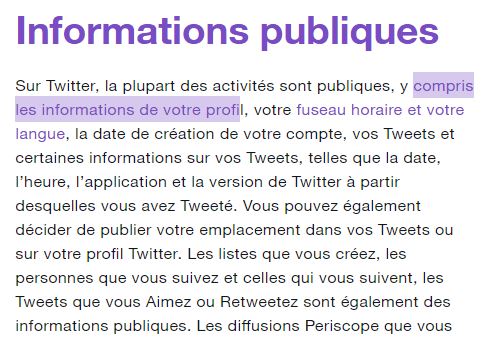
Et donc ils vous conseillent :

Car en plus de l'utilisation du site Twitter :

ils utilisent d'autres interfaces (API) pour diffuser en masse les contenus, moyennant rémunération. C'est le cas avec Visibrain.
Twitter insiste (source) :

d'autant plus que c'est Twitter qui vend l'accès aux API qu'il a développées pour permettre de telles recherches... ( source) :


Donc Twitter indique qu'il vend vos contenus, par exemple "aux ONG", aux "Nations-Unies", par exemple pour lutter contre le "complotisme anti-vaccins" (dans les pays "à majorité musulmane") ou lutter contre "les épidémies" telles "la grippe".
C'est beau...
Bon, ok, dans l'écrasante majorité des cas, ce sera des entreprises telles Boeing pour savoir ce que les twittos disent d'elles (voire des "chercheurs" voulant connaitre vos opinions politiques) - mais on imagine qu'il ne faut pas se plaindre, puisqu'on vous dit que ça permet à des gens de ne pas mourir... Et Twitter est sympa ( source) :

Il ne vend pas vos messages privés ! (les messages publics étant bien entendu vendus, eux). Car attention, Twitter a des "valeurs fondamentales" ( source) :

Et la "confidentialité" en fait partie. Ils font donc très attention dans leurs "prises de décision" - comme, par exemple, quand ils autorisent Visibrain à accéder à l'historique Twitter depuis 2006... Mais c'était prévu ( source) :

En conclusions, certains d'entre vous se diront peut-être : "Mais où le mal, ce sont des données publiques ?". Eh bien nous illustrons le problème dans la partie suivante...
III. Quand EU DisinfoLab joue avec Big Brother
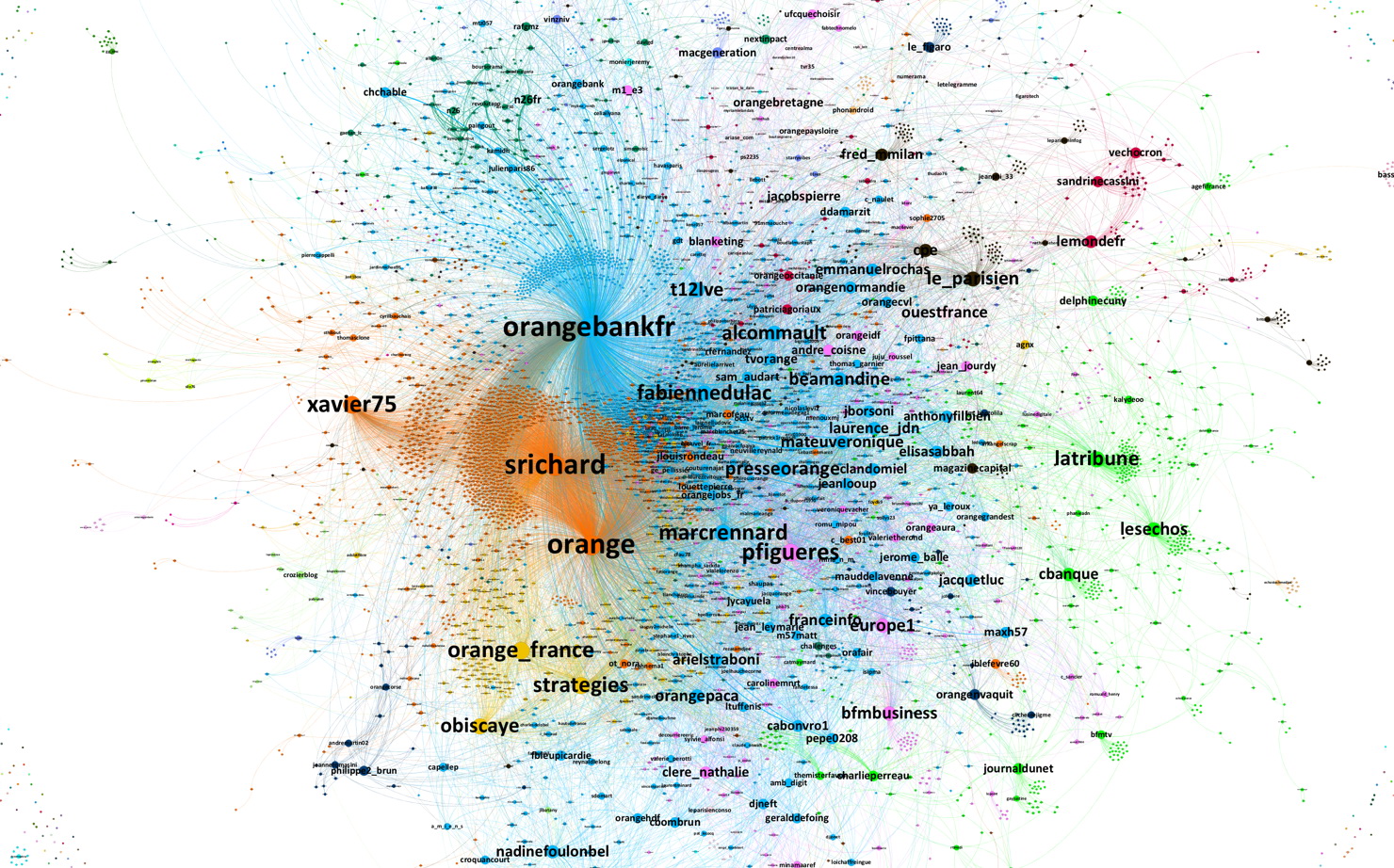
Nicolas Vanderbiest a donc utilisé Visibrain pour réaliser ses études. Dans la première (diffusée rapidement, plus orientée communication), au-delà des chiffres de volume (que fournit automatiquement le logiciel), il indique avoir réalisé ceci :
"4 communautés sont identifiées : une autour de la droite, des républicains et de l'extrême droite. (Plus on est à gauche, plus on est proche de la communauté d'extrême droite, en bas, on est plutôt républicains, et au-dessus, ce sont des sources médiatiques traditionnelles) ; une autour de la France Insoumise, qui vise particulièrement Gerard Collomb, une communauté médiatique, plus partagée par les personnes de gauche et enfin une communauté d'isolés qui par leurs tweets, ont élargi l'audience. "
Il illustre ceci avec ce graphique :
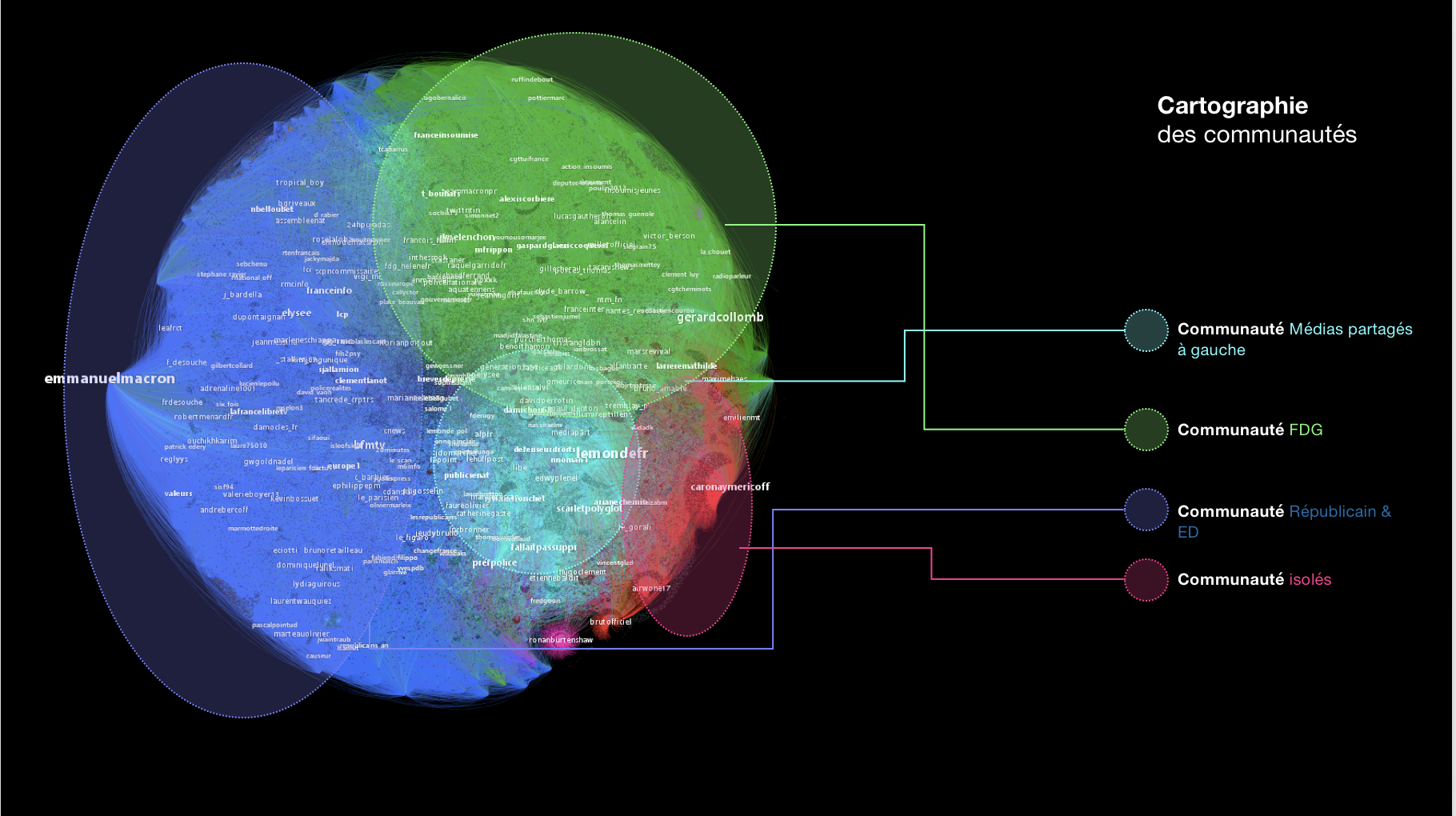
qui contient des noms de comptes :
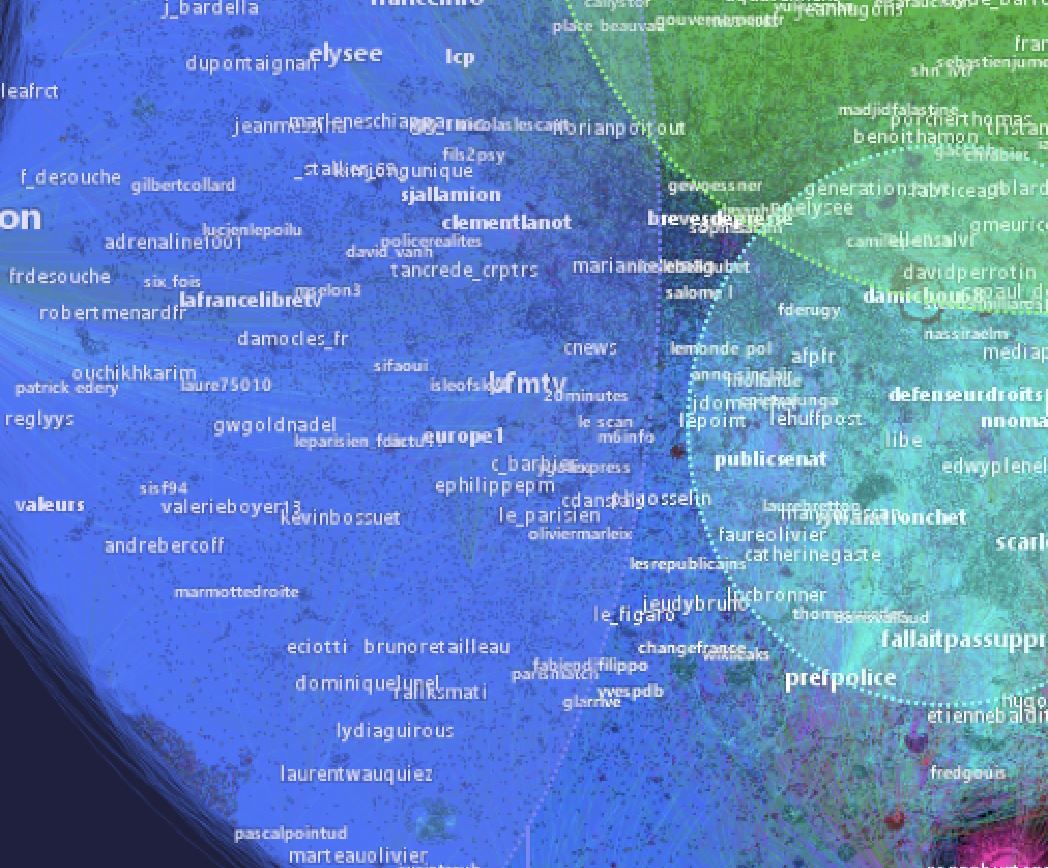
Il indique aussi ceci :
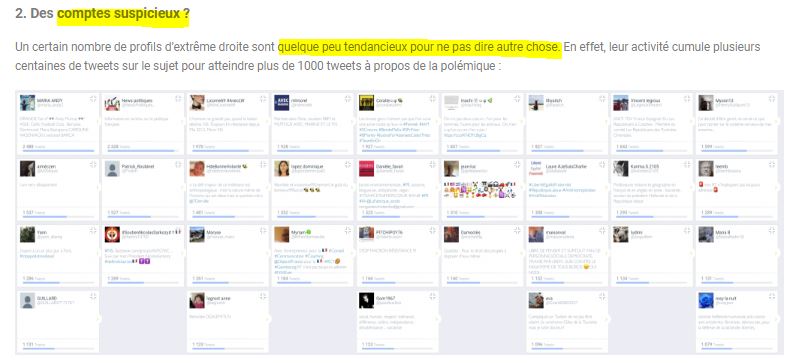
"Un certain nombre de profils d'extrême droite sont quelque peu tendancieux pour ne pas dire autre chose. En effet, leur activité cumule plusieurs centaines de tweets sur le sujet pour atteindre plus de 1000 tweets à propos de la polémique : " et il ajoute donc ce graphique :
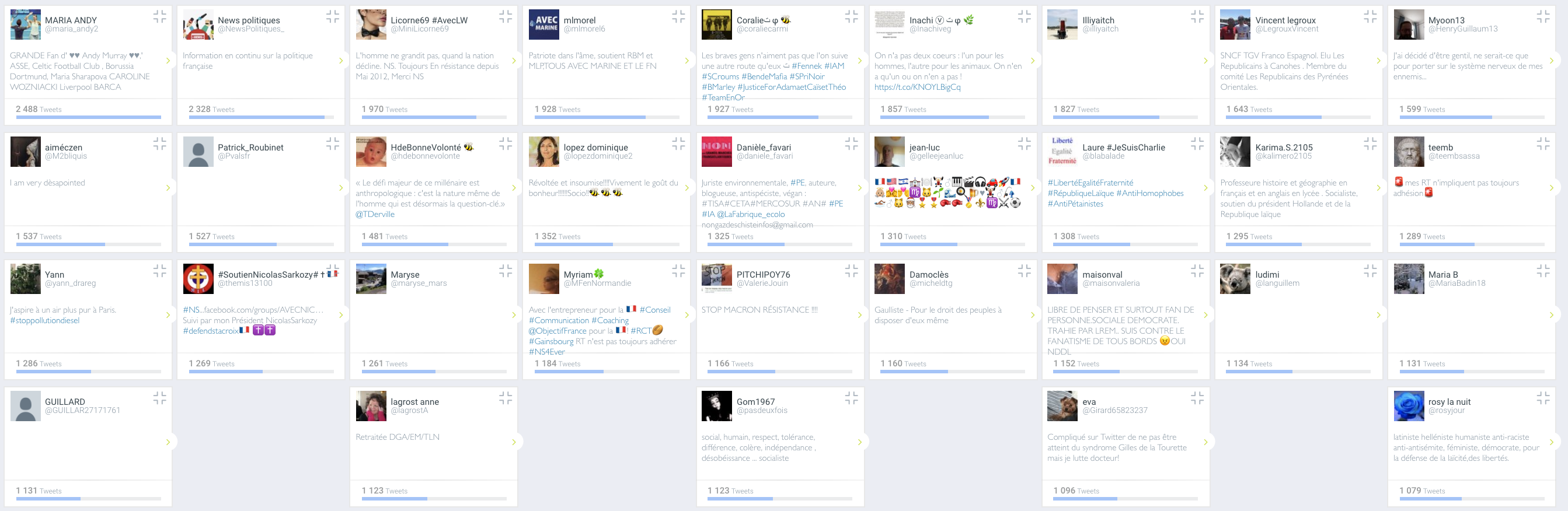
Quand on lui fait remarquer que certains comptes ne sont pas d'extrême droite, Nicolas Vanderbiest répond avec sa rigueur académique ( source - archive) :
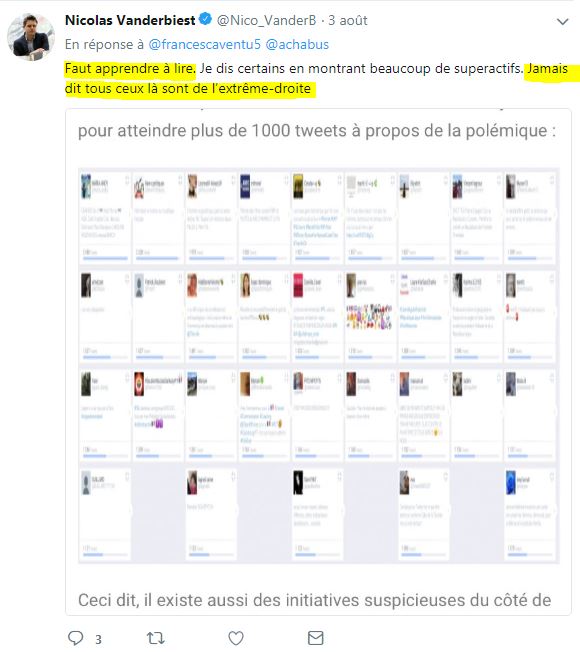
#FautApprendreÀLire...
Quand la professionnelle des médias sociaux Stéphanie Lamy le questionne sur le cas d'un twittos, Vincent Legroux, il répond ceci ( source - archive) :
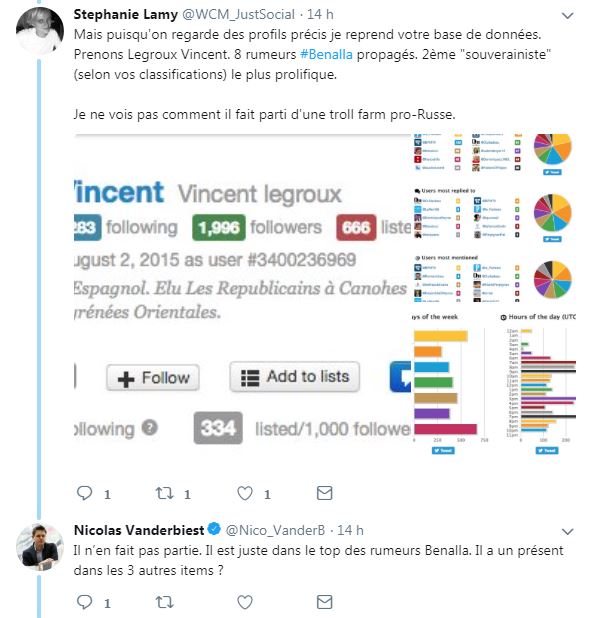
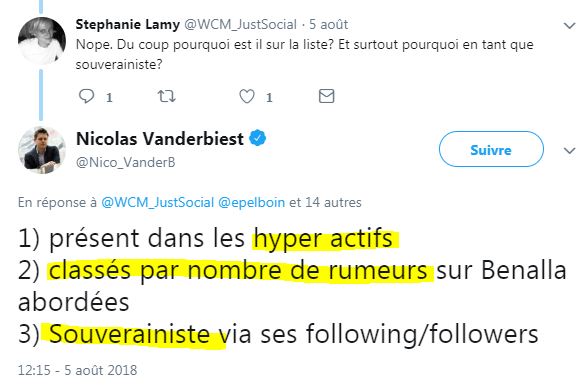
Tiens donc, il en sait des choses Nicolas Vanderbiest...
Et pour les insoumis ? ( source - archive)
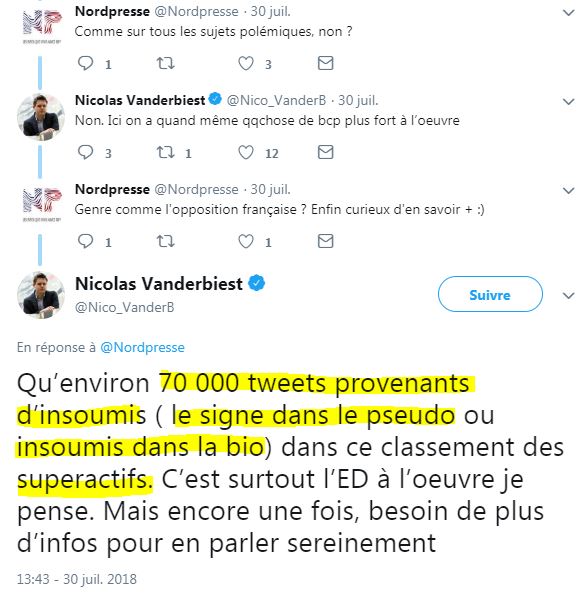
Ne rigolez pas, c'est scientifique !
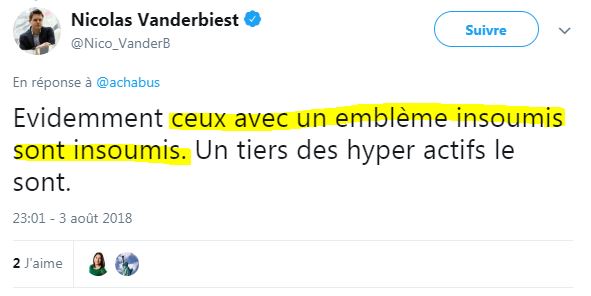
#Évidemment... Car c'est super précis comme méthode :
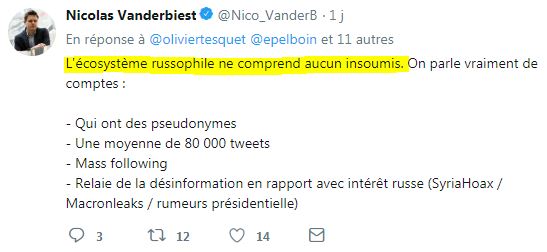
Ça se saurait si des insoumis avaient déjà relayé des infos de RT ou Sputnik !
Et sur les macronistes ?
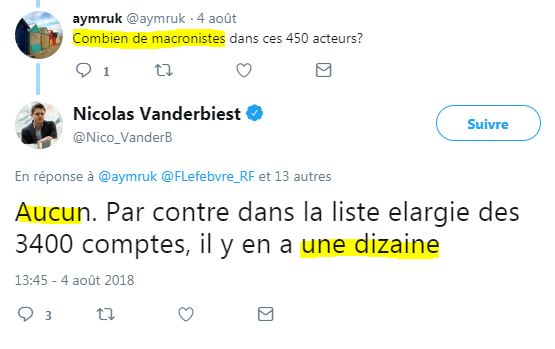
Tiens donc, il en sait des choses Nicolas Vanderbiest...
Il indique même :
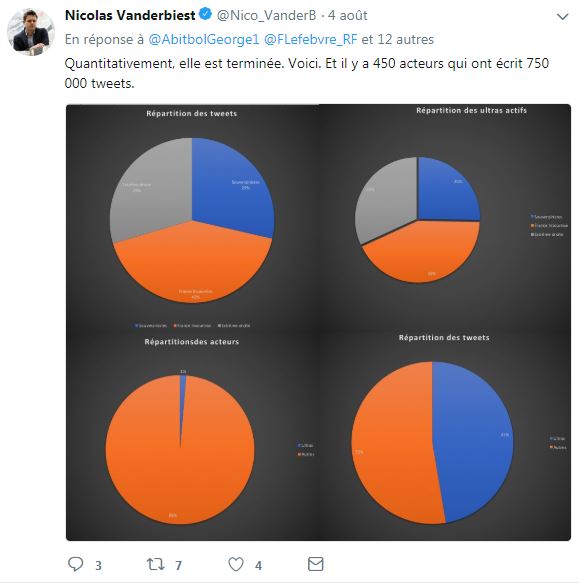
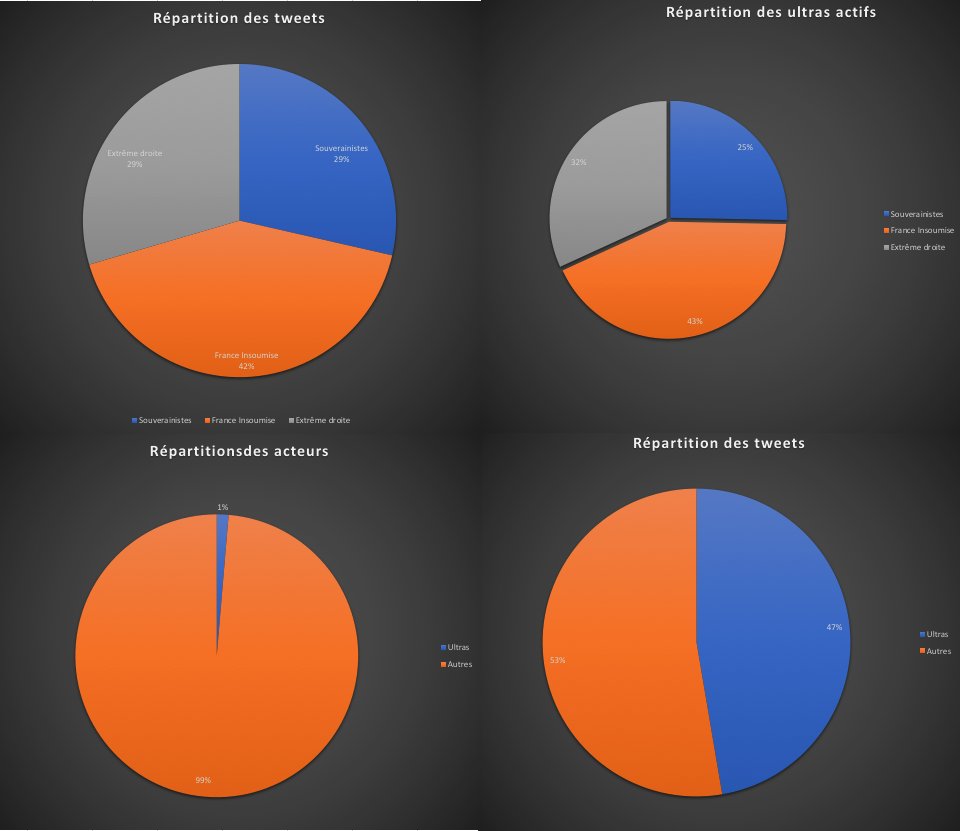
On parle apparemment bien ici des 4 millions de tweets (les hyperactifs sont dans l'autre camembert) :
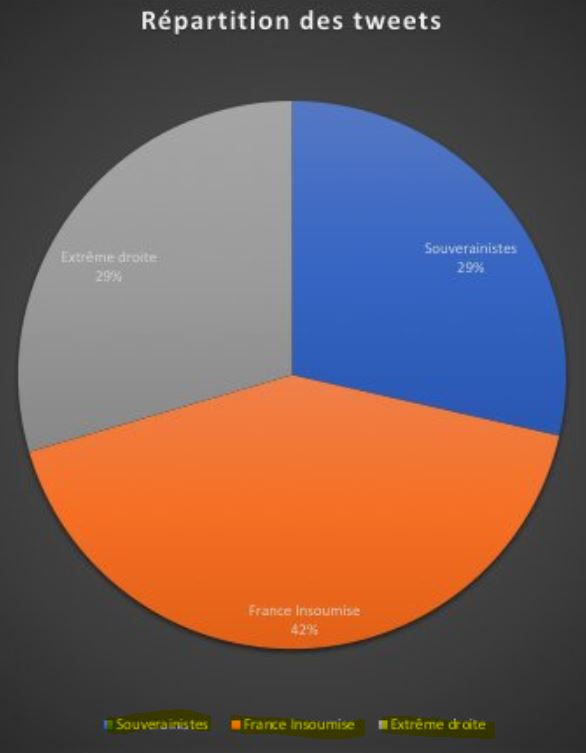
Tiens donc, il en sait des choses Nicolas Vanderbiest...
Il ne peut faire son étude que s'il a un algorithme pour classer politiquement les comptes Twitter - ce qui n'a rien de très difficile en fait...
L'avantage c'est qu'on le sait, car il n'est pas très cachotier...
IV. "Et c'est le drame..." : la diffusion des données personnelles
En effet, le chercheur d'EU DisinfoLab a indiqué ( source - archive) :

C'est un habitué de la chose, notez - si vous voulez la liste des "russophiles" anglais aussi, pour une étude sur le "Brexit" (sic.) :
Ainsi, il indiquait ici à Samuel Laurent qu'il allait partager la base de données quand il aurait fini :
Et donc... Il l'a fait ! ( source) :
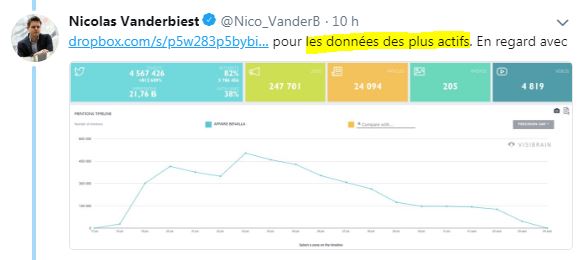
Il a d'abord partagé publiquement via Dropbox le fichier des 55 000 plus gros diffuseurs de Tweets et Retweets (ayant diffusé entre 7 et 12 158 tweets), avec toutes leurs informations personnelles :
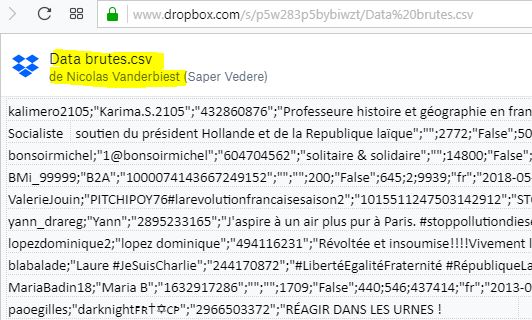

Cliquez pour agrandir
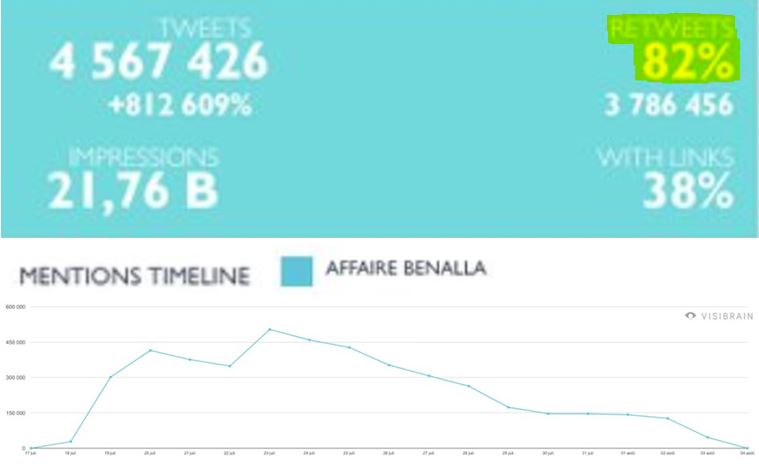
Rappelons de nouveau qu'1 retweet est compté comme un tweet, et que 82 % des "tweets" annoncés dans l'étude sont des retweets ( source) :
Puis ensuite, Nicolas Vanderbiest a fait beaucoup mieux : il a diffusé publiquement ceci ( source - archive) :
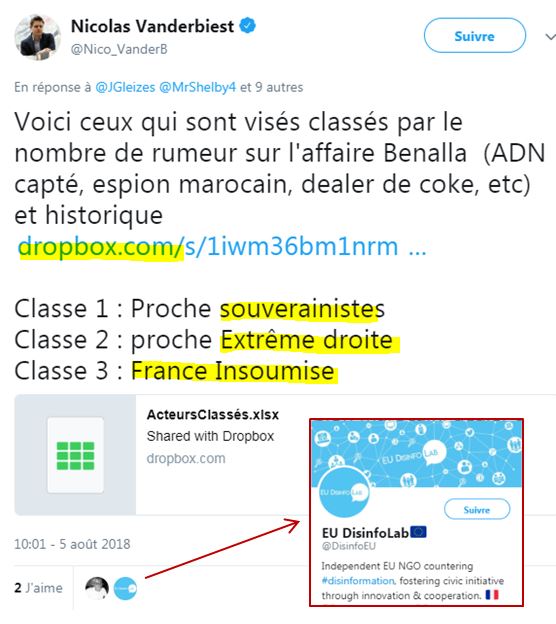
à savoir un fichier avec les 3 392 plus gros twitteurs sur Benalla (qui sont donc surtout des retwitteurs), auxquels il a attribué une couleur politique via un algorithme qu'il a créé : 1 pour souverainistes (sic. - c'est la droite Républicaine), 2 pour Extrême-droite et 3 pour la France insoumise ! Et son tweet a été liké par EU DisinfoLab...

Analysons ce fichier dans la partie suivante.
V. Le fichage politique (mais pas que) par EU DisinfoLab
Le fichier des 3 392 plus gros twitteurs sur Benalla se scinde ainsi par couleur politique (selon la définition et l'algorithme EU DisinfoLab) :

Bien entendu, nous ne diffuserons pas le fichier sur ce site. Mais nous vous montrerons un court extrait sur quelques très gros comptes, afin que chacun perçoive bien l'étendue du problème. (mais le mal est fait, car la liste a été largement diffusée sur Twitter)
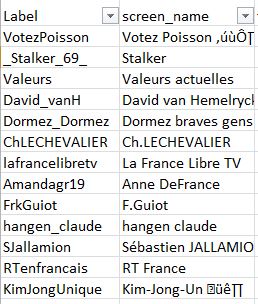
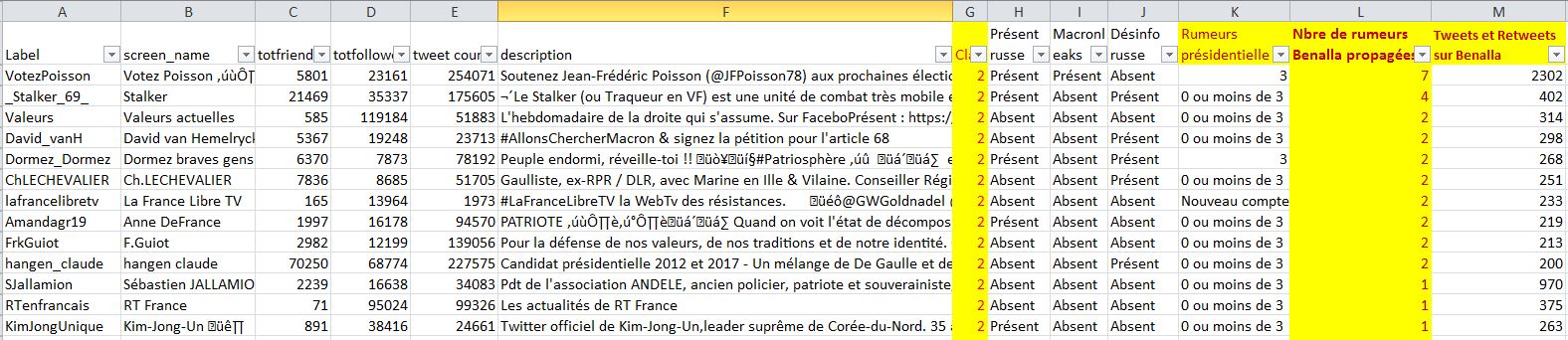
Voici donc pour ces quelques gros comptes "Classe 3 : France Insoumise" :
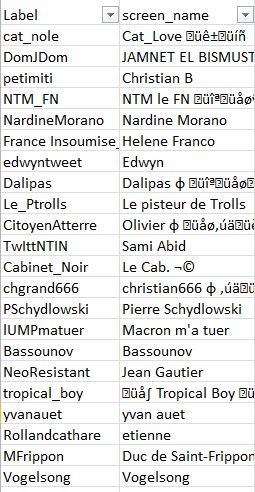
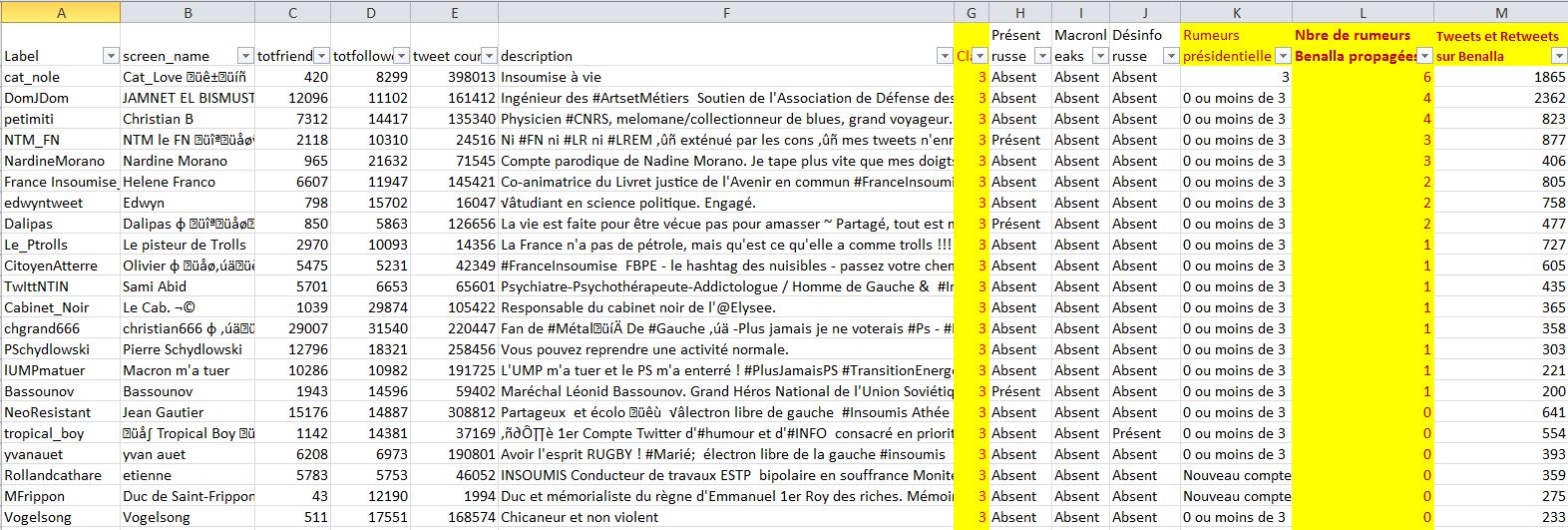
Cliquez pour agrandir
Vous voyez en colonne G la classification réalisée par Nicolas Vanderbiest, en colonne K le nombre de rumeurs/désinformations diffusées durant la présidentielle 2017 (voir ci-après pour une précision sur cette colonne), en colonne M le nombre de tweets et retweets en lien avec l'affaire Benalla et en colonne L le nombre de rumeurs/désinformations liées à l'affaire Benalla...
Voici un deuxième exemple pour ces quelques gros comptes "Classe 1 : Proche Souverainistes" (sic.) :
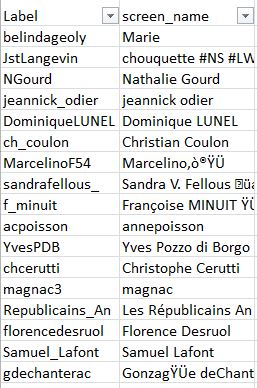
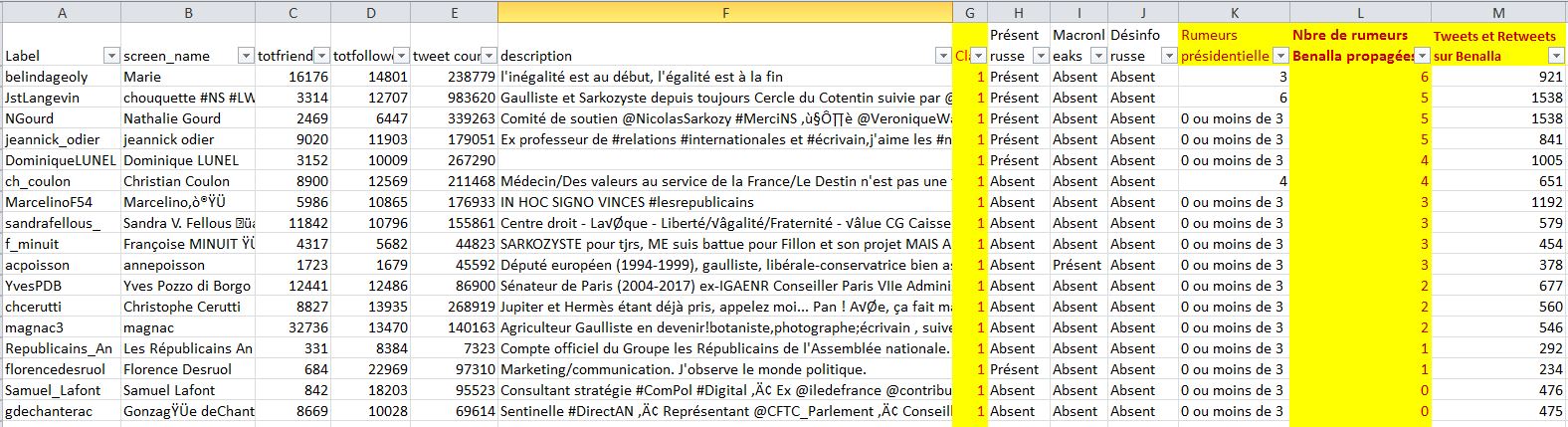
Voici un troisième exemple pour ces quelques gros comptes "Classe 2 : Proche Extrême-droite" :
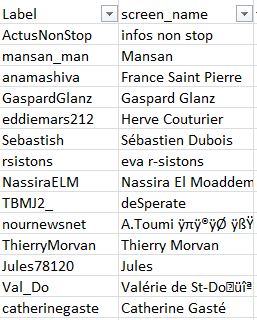
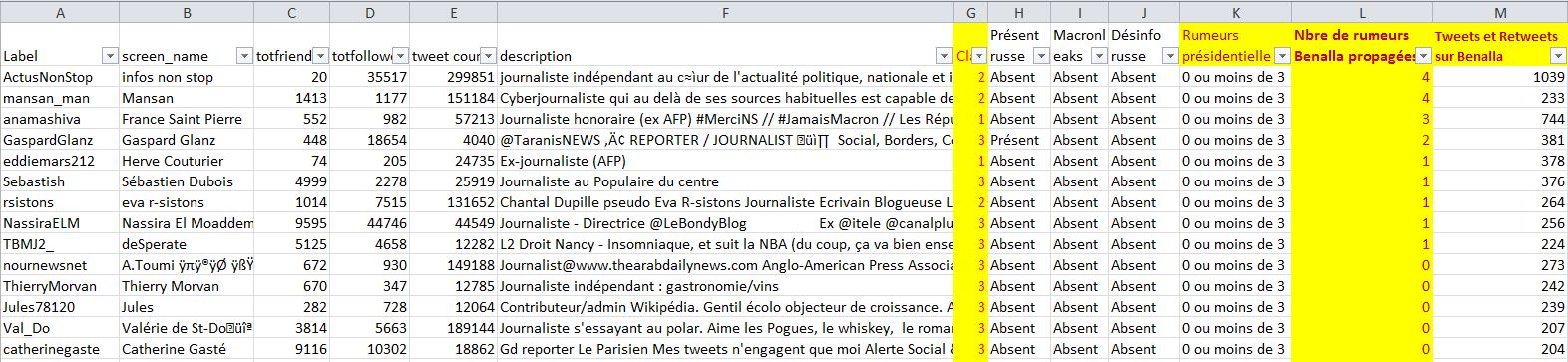
Mais vous notez que figurent aussi dans ce fichier les informations biographiques, en colonne E. Nous vous présentons donc un extrait avec quelques grands comptes de... journalistes :
Peut-être que maintenant notre choix de "Big Brother" se justifie-t-il plus clairement ?
D'ailleurs EU DisinfoLab a également mis le 8 aout à disposition 2 autres fichiers, avec moins de données personnelles "pour être transparents" ( source) :
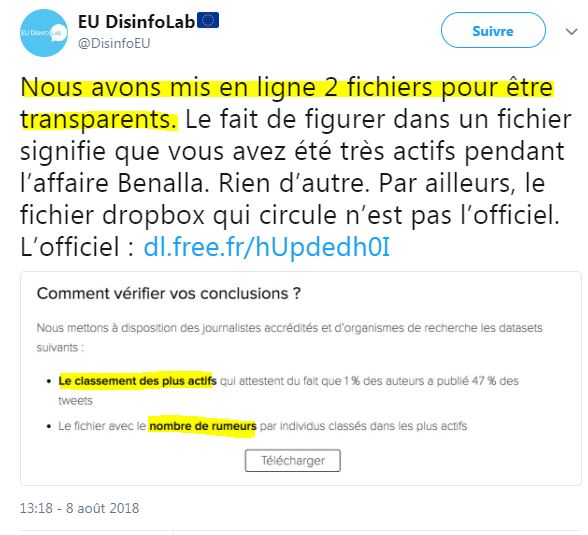
En effet ( source) :
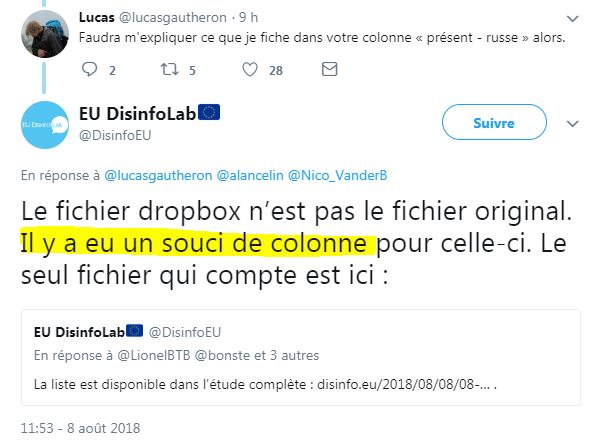
#IlYAEuUnSouciDeColonne
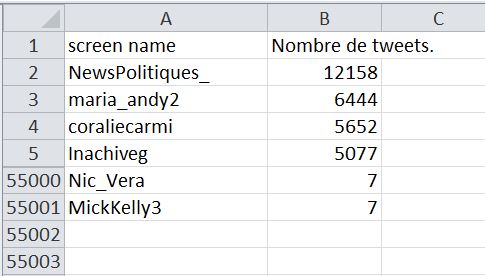
Le premier comprend un classement des 55 000 comptes les plus actifs sur Benalla avec simplement le nombre de tweets :
Et un second fichier comprend des informations sur 3 890 comptes les plus actifs avec le nombre de prétendues désinformations sur l'affaire Benalla :
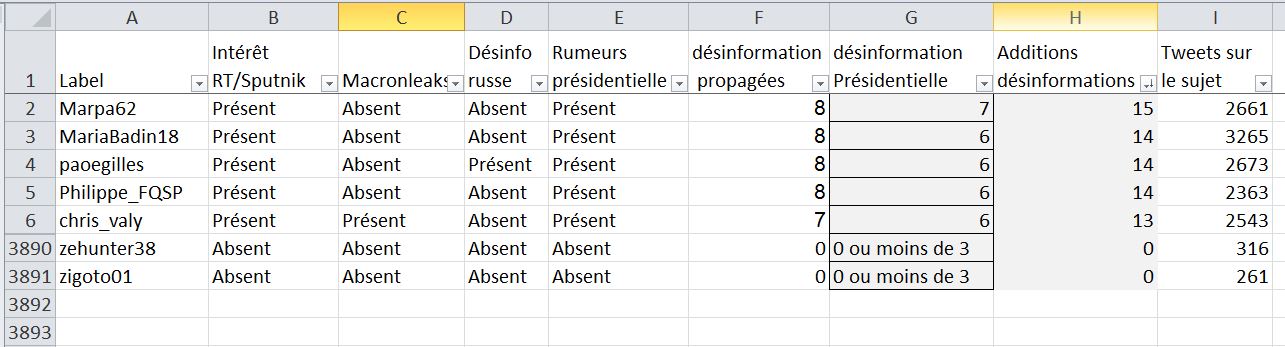
(Note : la colonne G détaille le nombre de désinformations lors de la Présidentielle. La colonne K du fichier de Nicolas Vanderbiest étant erronée, nous avons remplacé dans nos captures précédentes cette donnée par celles issues de ce fichier)
Vous pouvez donc regarder si votre compte Twitter a été fiché (mais en fait ils ont fiché 100 % des comptes...) et surtout classé politiquement (c'est le cas au moins si vous figurez dans les 3 800 détaillés) en téléchargeant ces fichiers ici.
L'équipe a d'ailleurs précisé comment avait été faite la limitation du second fichier : ce sont toutes les personnes qui ont fait 200 tweets ET retweets en 10 jours, le 200 étant défini pour arriver à environ 1 % de tous les twitteurs sur le sujet...
Précisons enfin une chose, vu que nous avons ces données ; on obtient facilement ceci sur Excel :
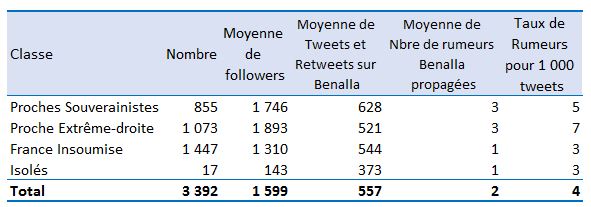
Ainsi, alors que Twitter n'aura eu à l'évidence qu'une influence bien limitée sur le développement de l'affaire Benalla (qui s'étalait dans tous les grands médias), on se rend compte, en plus, que le nombre de "rumeurs" (notion discutable que nous discuterons dans un autre billet) aura été de l'ordre, en moyenne, de 3 à 7 pour 1 000 tweets diffusés à 1 600 comptes en moyenne (seule une petite fraction les ayant vus) !
Ces chercheurs mettent ainsi en place des fichages généralisés de la population pour des phénomènes totalement dérisoires !
VI. Communication de EU DisinfoLab
La journée du 8 a été riche en réactions de Twittos, ce qui a obligé EU DisinfoLab à réagir. Et ça tombe bien, car la structure a pour mémoire dans son orbite une agence de communication spécialisée sur les crises...


Application ( source) :
Quand on vous dit qu'ils fichent les gens - mais pas vous Alexandre, ça ira... ( source)
enfin sauf si c'est de la Désinformation Pro-Macron - mais oups, ce n'était pas dans les définitions retenues par le rédacteur...
Mais c'est toujours sympa d'avoir son certificat par la police, surtout sur des bases aussi solides.

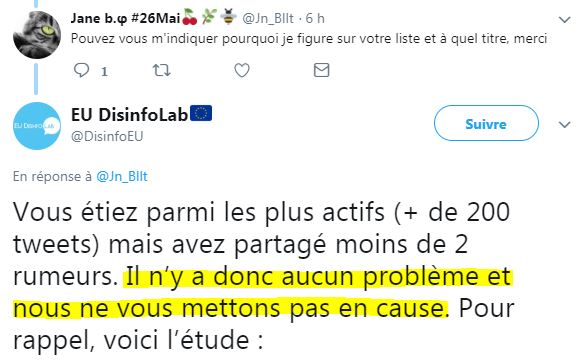
Jane, pas de souci, moins de 2 rumeurs, ça va... (c'est scientifique). Vous pouvez circuler. ( source)
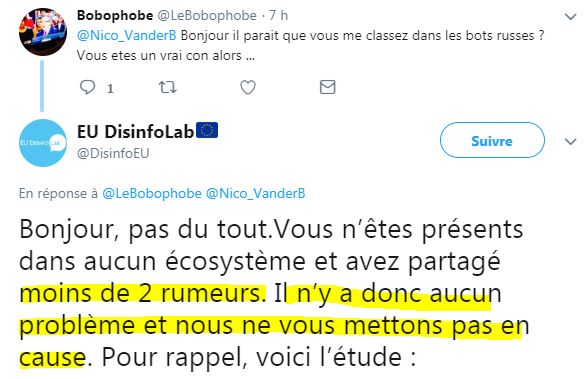
Vous aussi BoboPhobe, vous pouvez circuler - mais pensez à changer de pseudo, ça ne plait pas à Macron, merci. ( source)
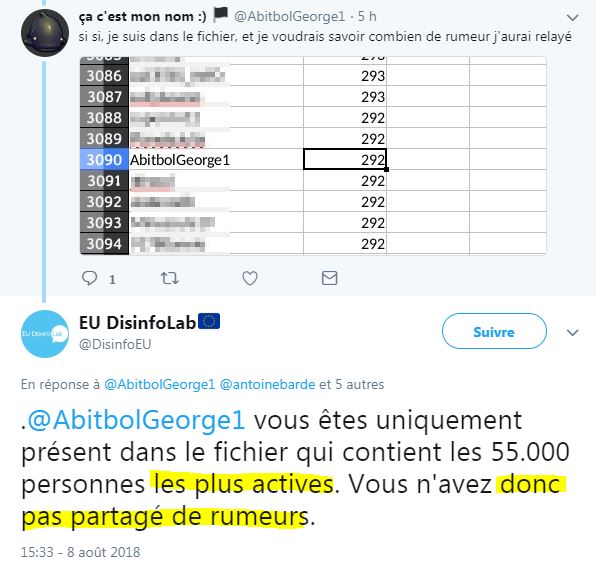
Rassurez-vous George, tout va bien. Vous êtes un bon citoyen (N.B. : on voit que le "donc" est erroné, le critère pour figurer dans l'autre fichier étant (a priori) d'avoir fait 200 tweets, et non pas d'avoir diffusé au moins une rumeur...) ( source)
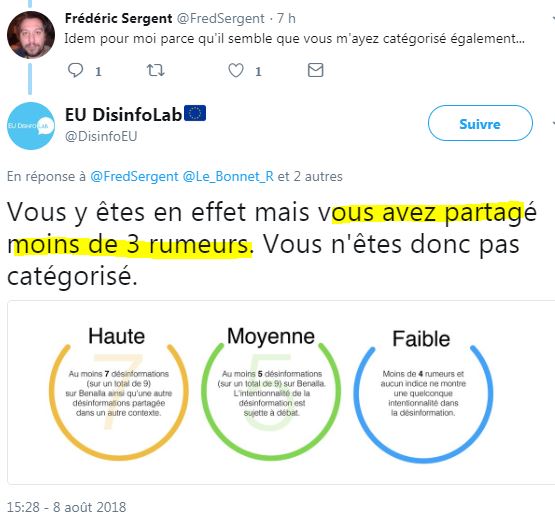
Tssss Frédéric, tu as trop tweeté sur l'affaire Banalla. La prochaine fois, on te conseille de faire 1 tweet sur Benalla et immédiatement après 1 tweet pro-Macron. Comme ça, plus de problème avec la police ! Après, si tu veux être sûr que Benalla ne vienne pas te voir en personne, contente-toi uniquement de faire des tweets pro-Macron, c'est plus sûr... ( source)
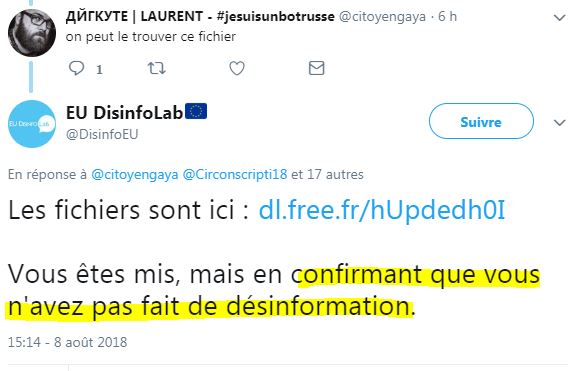
Allez, Laurent ça ira pour cette fois... Mais change le hashtag immédiatement ou on t'envoie Benalla ! ( source)
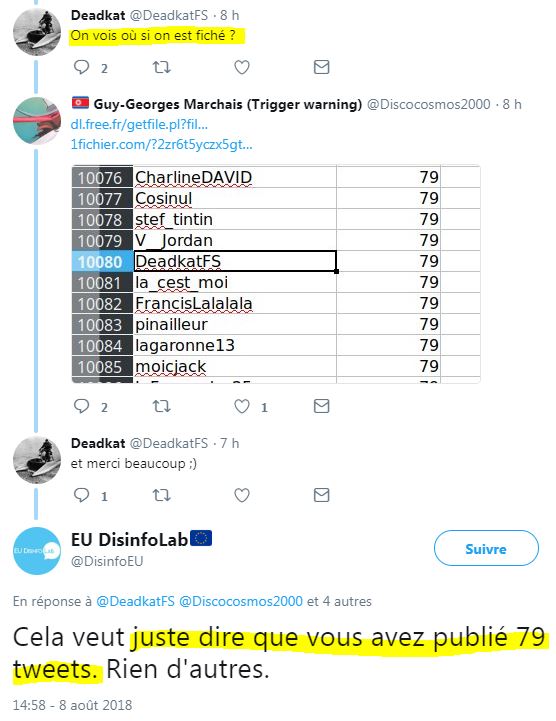
Eh oui, Deadkat, tout va bien, t'es juste fiché ! #RienDAutre. Bon ne dépasse pas 13 tweets la prochaine fois, et ça ira ! ( source)
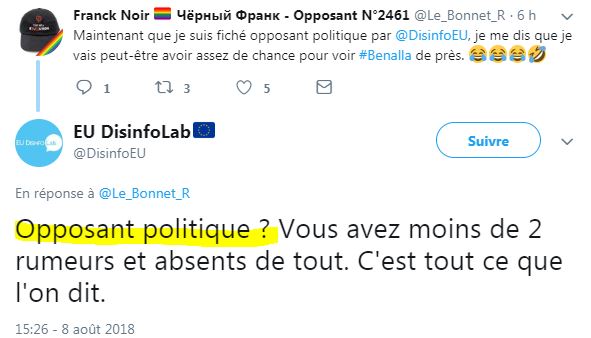
"Opposant politique" - tout de suite les grands mots. Ils n'ont jamais dit ça ! ( source)
Enfin, sauf dans leur fichier hein - classe 3, alors comme ça on fricote (peut-être ?) avec Mélenchon, Franck ?
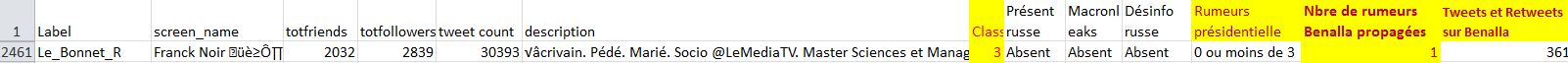
En fait, le tout est de ne pas désinformer. Et en l'espèce, le nouveau Code Pénal d'Internet, établi sur des bases scientifiques, est très clair ( source) :
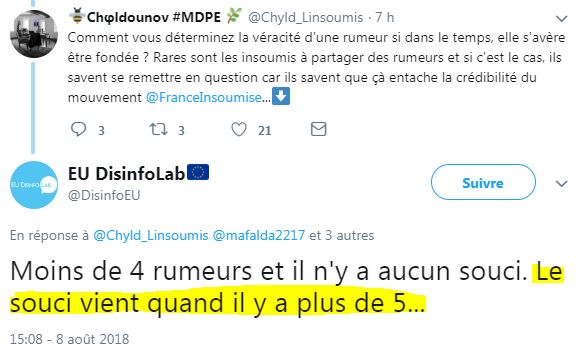
Tu vois Chyld, c'est vraiment terrible 5 rumeurs. Il y en a qui ont essayé, et ils ont eu des problèmes... ( source)

Mais n'ayez pas peur, la brigade d'intervention contre la Désinformation est en route et va rapidement maitriser la forcenée.
VII. Position de EU DisinfoLab quant aux données sensibles
Ce n'est pas la première fois que se pose ce problème.
Nicolas Vanderbiest a déjà réagi l'année dernière suite à la diffusion de ceci (ah, c'était encore les Russes...) :
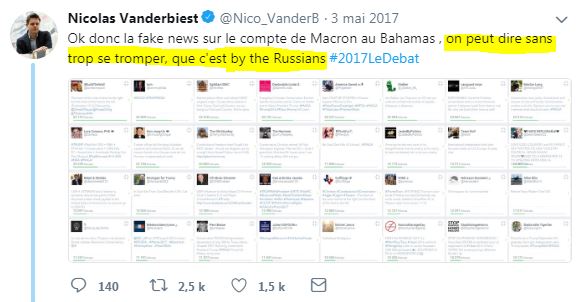
une personne citée avait réagi :
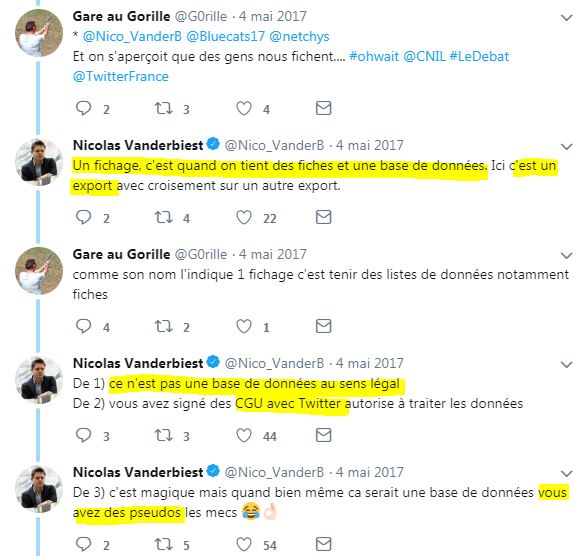
#C'EstPasUnFichage #C'EstUnExport #PasUneBaseDeDonnéesAuSensLégal
Il n'y a apparemment pas eu de mise à jour des connaissances depuis... Car des twittos se sont rapidement plaints à l'auteur (source) :
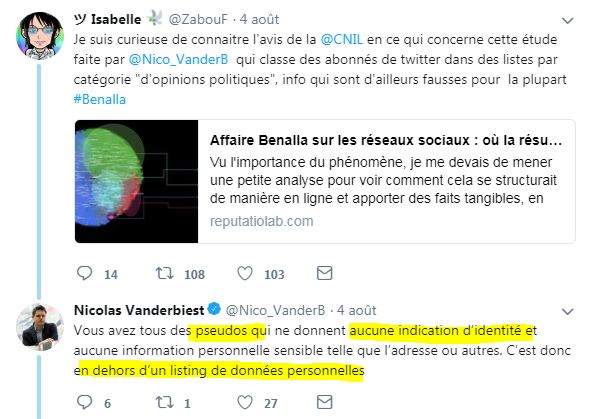
Eh oui il n'y a que des pseudos !
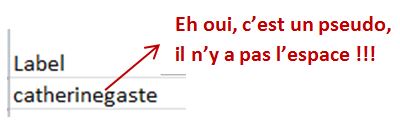
Mais :
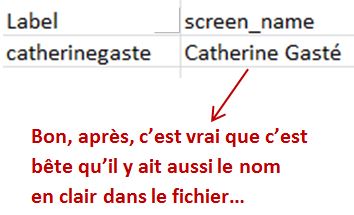

Après, quand on parle directement à DisinfoLab du RGPD, le Règlement européen de protection des données personnelles qui vient d'entrer en vigueur, ils expliquent qu'il ne faut pas s'inquiéter, car ils n'ont fiché que 55 000 personnes :
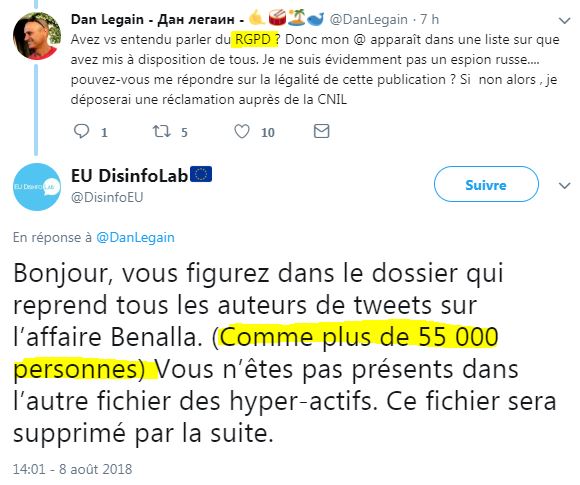
Et puis le fiché sera bientôt "supprimé" - ce n'est pas comme les gens l'avaient téléchargé et que des copies circulaient hors de tout contrôle hein ! ( source)
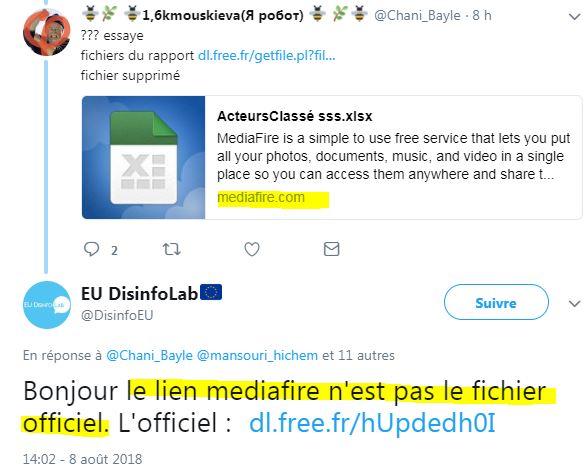
Et d'ailleurs, EU DisinfoLab explique que c'est à cause du RGPD (donc la règlementation de protection des données) qu'ils sont obligés de publier le fichier de données personnelles et sensibles ( source) :
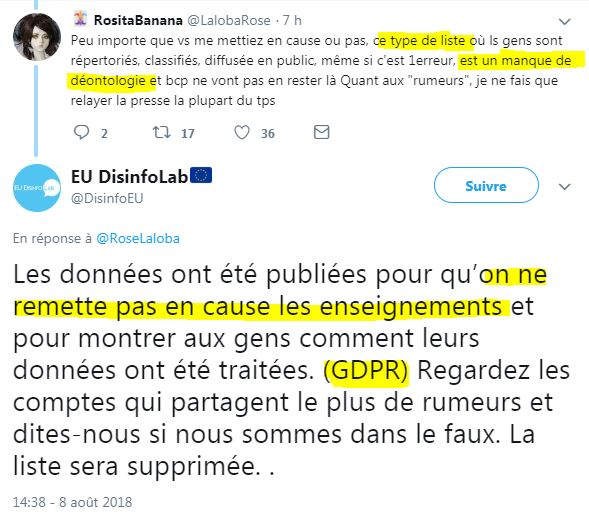
Voici d'ailleurs la réaction officielle de M. RGPD à la CNIL ( source) :

Merci M. RGPD.
VIII. Le CNRS a aussi fiché les opinions politiques de près de 200 000 personnes !
Dans le cadre de nos recherches, nous sommes tombés sur cet article des Décodeurs du Monde du 4 décembre 2017 :
Adrien Sénécat nous indique qu'ils ont pu croiser "une dizaine de bases de données sur la période électorale", lors de l'évènement Datapol :

Ils ont réalisé une première étude sur "les fausses informations" (définies selon les critères méthodologiques du... Décodex). Puis une seconde qu'ils titrent "Les partisans de Marine Le Pen partagent plus de sources peu fiables que les autres" :
"Un autre enseignement intéressant est apparu en croisant les données du Décodex avec celles du Politoscope. [...] À partir de cette typologie et des données anonymisées du Politoscope, les participants à Datapol ont donc pu regarder dans quelle mesure les différentes communautés politiques partagent plus ou moins de liens vers les différents types de sources d'information identifiées dans le Décodex."
L'infographie du Monde est ainsi construite :
- chaque candidat figure sur une tranche ;
- plus un point est éloigné du 0, plus la communauté proche du candidat correspondant a partagé le type de sources en question :
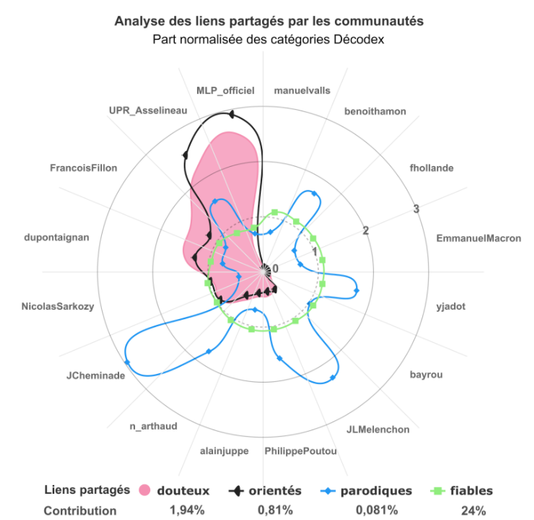
"Il apparaît ainsi que les partisans de Marine Le Pen et François Asselineau sont ceux qui, en moyenne, ont partagé le plus de liens vers des sources considérées comme peu fiables dans le Décodex. Une analyse qui mériterait d'être affinée par un travail approfondi, mais qui a le mérite d'apporter des données pour accréditer un comportement identifié par de nombreux observateurs pendant la campagne."
Avant de continuer sur notre axe, signalons quelques interrogations méthodologiques. D'abord, rappelons que la population des personnes inscrites sur Twitter n'est clairement pas représentative de la population générale (avec 49 % de CSP+ chez les 25-49 ans par exemple - source).
En fait le graphique a utilisé une présentation "douteuse". On a l'impression en regardant le graphique que les "communautés pro-Le Pen" et "pro-Asselineau" auraient inondé Twitter de liens vers des sites classés "très peu fiables". Or, les Décodeurs indiquent dans l'article que "lorsqu'un point est proche du cercle de rayon 1, cela veut dire que le type de contenus correspondant a été partagé dans les mêmes proportions que la moyenne. Lorsqu'il est proche du trois, cela veut dire qu'il a été trois fois plus partagé." Ils représentent donc un simple écart à la moyenne, d'un phénomène marginal, d'où les forts écarts observés, qui sont en fait peu représentatifs. Ceci apparaît en fait clairement quand on observe la courbe verte peu visible de la diffusion de sites "fiables" : il y a assez peu d'écarts entre les candidats en réalité.
Illustrons. Nous avons reconstitué à la main les données du diagramme des Décodeurs. On peut dès lors reconstituer simplement ce que donnerait un graphique plus honnête représentant la diffusion de liens vers les sites classés par le Décodex :
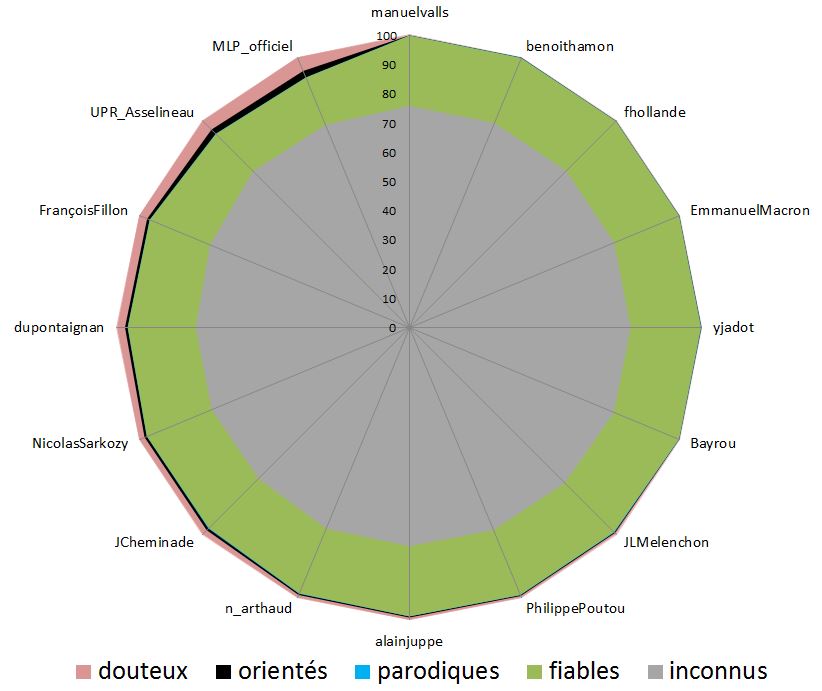
Ce graphique donne donc une impression fort différente au lecteur de l'activité des personnes sur Twitter...
Mais revenons au Politoscope de L'Institut des Systèmes Complexes Paris-Île-De-France (ISC-PIF, du CNRS). L'article insiste bien : "Dans le cadre de ce projet, l'équipe de l'Institut des systèmes complexes Paris Ile-de-France, un laboratoire du CNRS, a analysé sur la durée de la campagne les messages de milliers d'internautes sur Twitter. L'un des intérêts du Politoscope est qu'il identifie la proximité d'un utilisateur de la plate-forme avec tel candidat au fil du temps". Voilà ce qu'on trouve sur le site dédié du Politoscope qui explique ceci :


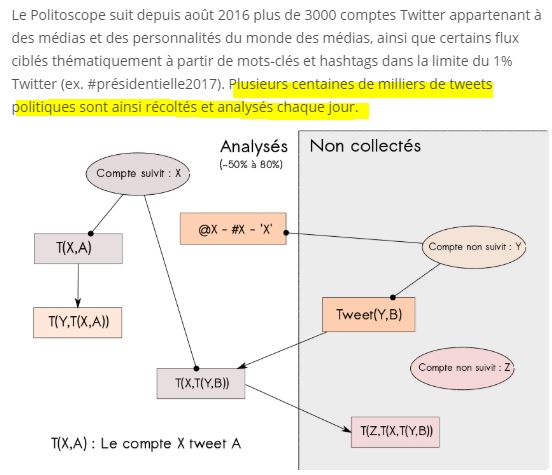

En fait, dans cette étude méthodologique, ils expliquent qu'ils sont partis de 3 700 comptes Twitter de figures politiques françaises, dont ils recueillent ainsi les tweets, mais surtout toutes les informations lors de retweets de ceux-ci ou de réponses (cf schéma précédent):


Et partant de là - vous le voyez venir -, quand l'échantillon de tweets est suffisamment important, ils peuvent (eux-aussi) inclure un compte dans une "communauté politique" :

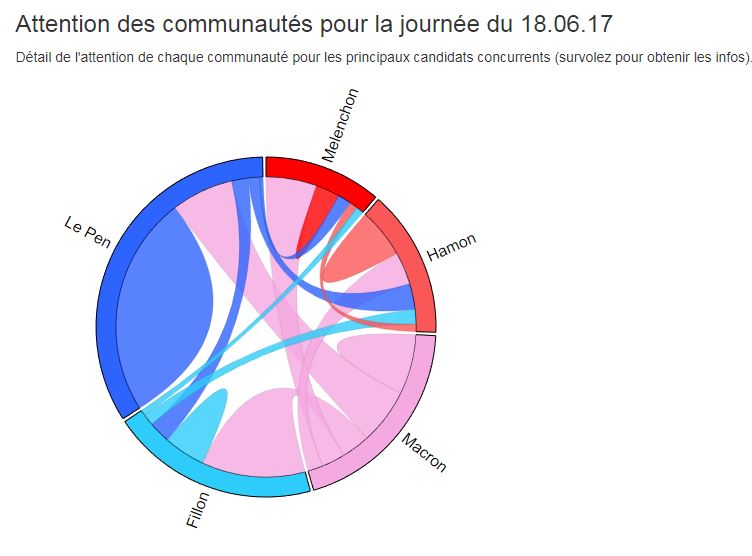

Et ils font alors des statistiques :
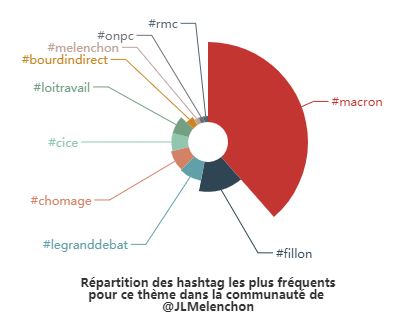
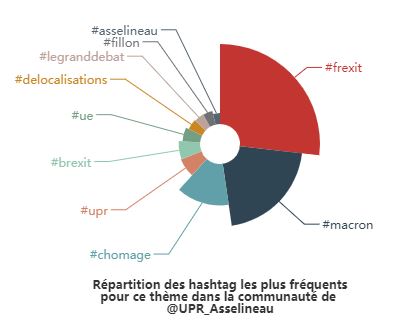
Et on apprend alors (discrètement) combien de comptes ils ont ainsi classé politiquement durant la présidentielle : 187 619 !
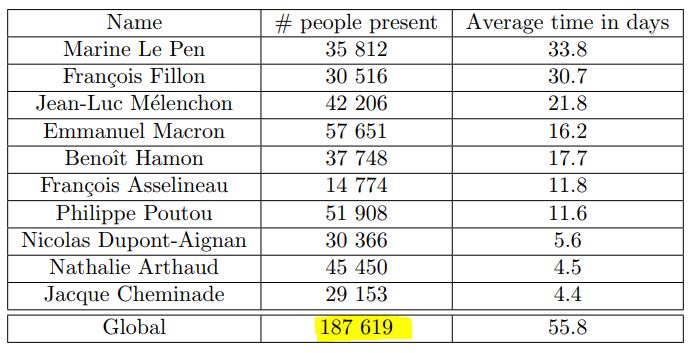
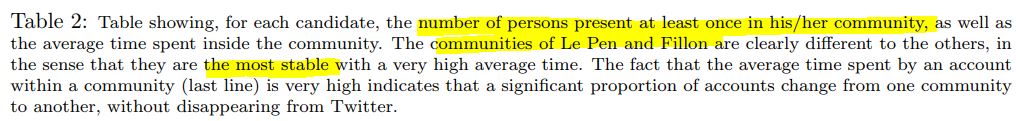
Si on cumule chaque ligne, on arrive à un total 375 000 personnes, car leur méthode est assez frustre (ils n'analysent pas le contenu des tweets par exemple). Ainsi une personne peut-elle est comptée comme pro-Poutou une semaine, puis pro-Arthaud la suivante, puis pro-Mélenchon la suivante, selon ses retweets (car cette sensibilité politique a plusieurs candidats possibles proches). Mais on voit que les auteurs indiquent que les communautés définies comme pro-Le Pen et pro-Fillon sont très stables... (sic.)
Et le plus fort est que leur opération ne s'est pas terminée avec la présidentielle - la base a doublé depuis :

Le Politoscope en est à plus de 126 millions de "tweets politiques", émanant de plus de 6 millions de comptes Twitter ! (dont une seule fraction est analysée politiquement comme on l'a vu)
L'avantage du CNRS, cependant, est qu'ils ne diffusent pas la base publiquement - mais évidemment, la simple existence d'un tel fichier pose de très lourds problèmes - sachant que n'importe quel gros utilisateur de Visibrain (ou de l'API de Twitter directement) peut faire de même, et largement perfectionner les attributions politiques s'il le souhaite...
Big Brother ?
IX. Réglementation et Discussion
Rappelons que le Code pénal précise ceci :
Article 226-16
Le fait, y compris par négligence, de procéder ou de faire procéder à des traitements de données à caractère personnel sans qu'aient été respectées les formalités préalables à leur mise en oeuvre prévues par la loi est puni de cinq ans d'emprisonnement et de 300 000 euros d'amende.Article 226-18
Le fait de collecter des données à caractère personnel par un moyen frauduleux, déloyal ou illicite est puni de cinq ans d'emprisonnement et de 300 000 euros d'amende.Art. 226-19
Le fait, hors les cas prévus par la loi, de mettre ou de conserver en mémoire informatisée, sans le consentement exprès de l'intéressé, des données à caractère personnel qui, directement ou indirectement, font apparaître les origines raciales ou ethniques, les opinions politiques, philosophiques ou religieuses, ou les appartenances syndicales des personnes, ou qui sont relatives à la santé ou à l'orientation ou à l'identité sexuelle de celles-ci, est puni de cinq ans d'emprisonnement et de 300 000 € d'amende.Art. 226-22
Le fait, par toute personne qui a recueilli, à l'occasion de leur enregistrement, de leur classement, de leur transmission ou d'une autre forme de traitement, des données à caractère personnel dont la divulgation aurait pour effet de porter atteinte à la considération de l'intéressé ou à l'intimité de sa vie privée, de porter, sans autorisation de l'intéressé, ces données à la connaissance d'un tiers qui n'a pas qualité pour les recevoir est puni de cinq ans d'emprisonnement et de 300 000 € d'amende.La divulgation prévue à l'alinéa précédent est punie de trois ans d'emprisonnement et de 100 000 € d'amende lorsqu'elle a été commise par imprudence ou négligence.
L'article 8 de la loi n°78-17 du 6 janvier 1978 (CNIL) apporte toutefois un bémol :
I. - Il est interdit de traiter des données à caractère personnel qui révèlent la prétendue origine raciale ou l'origine ethnique, les opinions politiques, les convictions religieuses ou philosophiques ou l'appartenance syndicale d'une personne physique ou de traiter des données génétiques, des données biométriques aux fins d'identifier une personne physique de manière unique, des données concernant la santé ou des données concernant la vie sexuelle ou l'orientation sexuelle d'une personne physique.II. - Dans la mesure où la finalité du traitement l'exige pour certaines catégories de données, ne sont pas soumis à l'interdiction prévue au I :
1° Les traitements pour lesquels la personne concernée a donné son consentement exprès, sauf dans le cas où la loi prévoit que l'interdiction visée au I ne peut être levée par le consentement de la personne concernée ;
4° Les traitements portant sur des données à caractère personnel rendues publiques par la personne concernée ;
Il y a bien sûr deux types de données. Celles publiées par l'utilisateur, et celles déduites par des algorithmes à partir des précédentes.
C'est ainsi que, par exemple, Samuel Laurent a pu dire ceci, interpellé à propos des fichiers DisinfoLab :
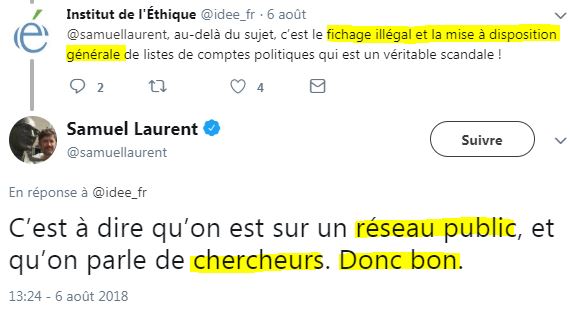
Ce n'est évidemment pas faux - pour la partie publique (et peut-on véritablement parler de "chercheurs" pour des personnes non universitaires ?).
Mais, première objection : quand ce jeune étudiant indique son nom et sa couleur politique, pour agir sur Twitter avec ses... 23 abonnés ;
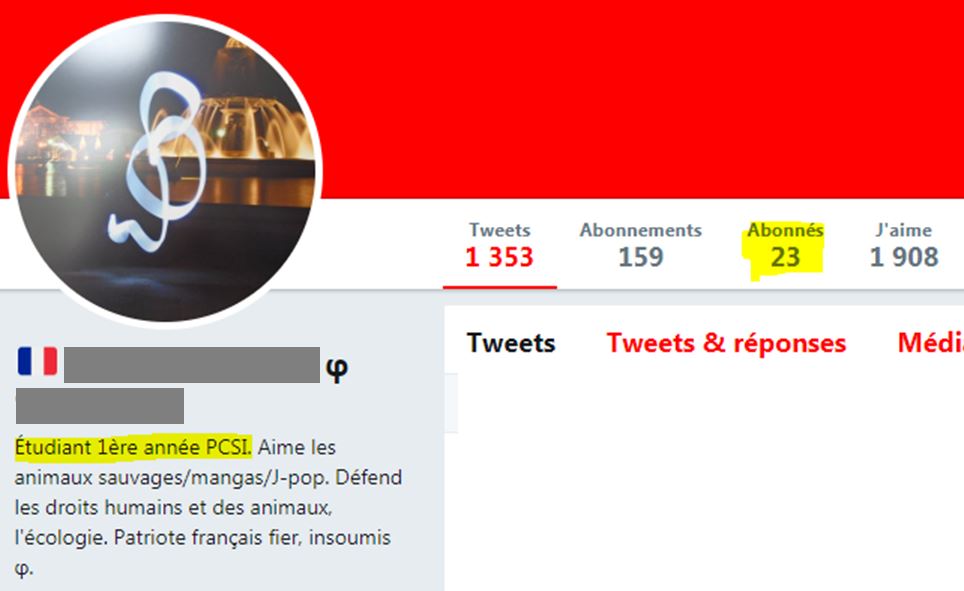
À t-il bien véritablement donné son accord pour que de nombreux analystes créent des fichiers avec son nom et ses opinions politiques ?
Il l'a certes dit publiquement sur Twitter, mais si c'est public, cela reste discret. Et un tweet s'oublie vite dans le fil, et le compte peut s'effacer. Mais ce n'est pas possible si des chercheurs créent des fichiers en permanence, non purgés.
Avec ce raisonnement, on pourrait d'ailleurs ficher plein de personnes : on vous reconnait en train de participer à une manifestation France Insoumise, vous sortez du local Les Républicains, vous avez défendu Macron dans l'affaire Benballa lors d'une discussion au bistro (surtout, ne prenez pas la route !). C'était public - peut-on vous ficher avec vos opinions politiques ?
Et par ailleurs, on peut vraiment se demander si "la finalité du traitement exige" une telle utilisation des données.
Au-delà, il faut bien comprendre que cette notion légale de "données rendues publiques", acceptable en 1976, ne l'est plus aujourd'hui. En effet, par exemple avec Twitter, il y a différentes façons de connaitre vos opinions politiques :
- vous l'avez dit en dur dans votre biographie ou votre libellé de compte, comme l'étudiant ci-dessus (public) ;
- vous l'avez dit dans un tweet le soir du 1er tour de la présidentielle (public) ;
- vous relayez surtout un dirigeant politique (inférence très probable) ;
- vous parlez en général de vos opinions de nature politique, sans être partisan - "il faut libérer les énergies, on paie trop d'impôts pour trop de fonctionnaires, etc." (inférence probable)
- vous parlez beaucoup de vous sur Twitter, vous suivez et retwittez beaucoup de personnes. Et c'est là que le Big Data peut inférer vos opinions politiques avec une précision que vous n'imaginez probablement pas. (inférence possible)
Ainsi, désormais, les pouvoirs publics ne doivent pas seulement s'occuper des données non publiques, mais également de la collecte et surtout la diffusion de masses de données publiques, en particulier sur les réseaux sociaux.
Twitter est ainsi gravement fautif - finalement bien plus que DisinfoLab ou le ISC-PIF du CNRS. Après tout, si vous donnez des millions de données à des chercheurs, certains finiront immanquablement par les utiliser ainsi...
Bref c'est bien les conditions d'utilisation de l'API de Twitter qu'il faut viser dans le combat pour la protection des données de la population ( source) :
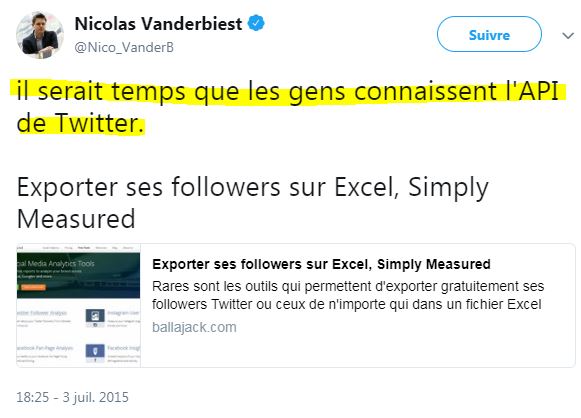

Quand on pense que la CNIL a été créée en 1978 après une vive émotion dans l'opinion publique suite à un projet gouvernemental visant à identifier chaque citoyen par un numéro et interconnecter, via ce numéro, tous les fichiers de l'administration - on se rend compte de l'énorme baisse de notre vigilance, et des risques pour les Libertés publiques...
X. Plainte
Nicolas Vanderbiest a déclaré :
Pour vérifier cela, j'ai porté plainte à la CNIL. - comme beaucoup
J'ai également mandaté mon avocat afin de prévenir le Procureur de la République de ces faits particulièrement graves.
Nous allons évidemment saisir également la CNIL belge et la CNIL irlandaise (siège de Twitter), ainsi que les Commission européenne.
Si des gens veulent nous aider pour agir à l'international, ou pour prévenir d'autres utilisateurs concernés et afin de grouper les plaintes, ou si vous êtes spécialiste de ce sujet de protection des données et pouvez nous aider, vous pouvez nous écrire ici.